The $47k Loop: Why Your AI Agent Needs a Circuit Breaker

Search for a command to run...
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
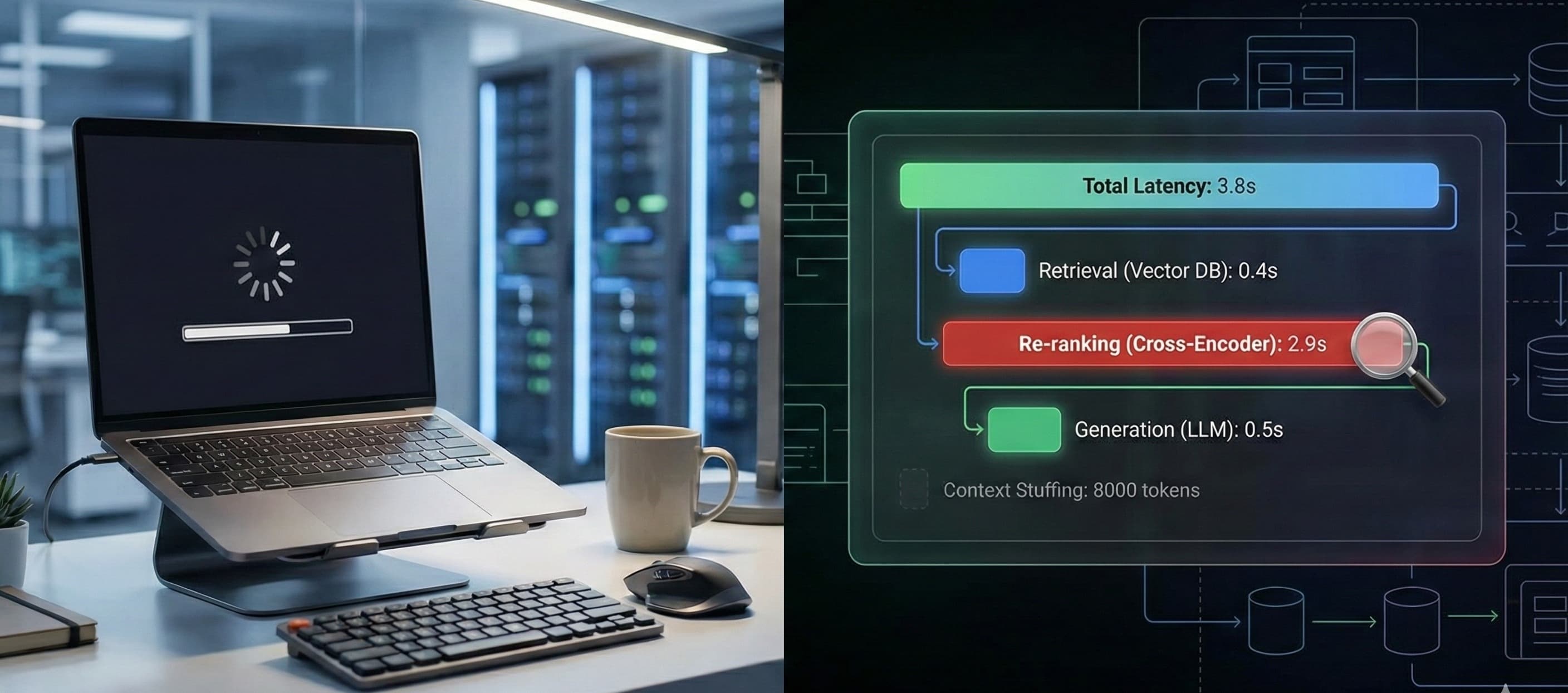
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
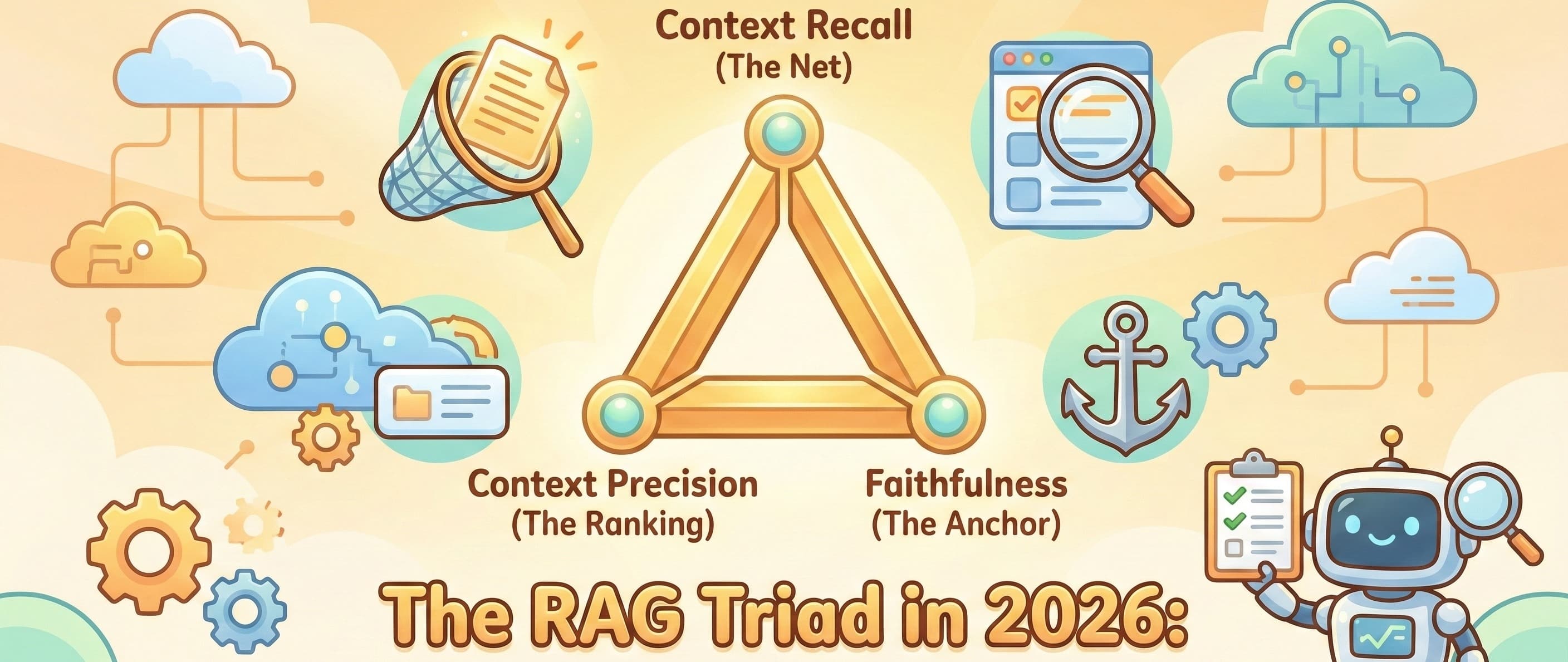
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
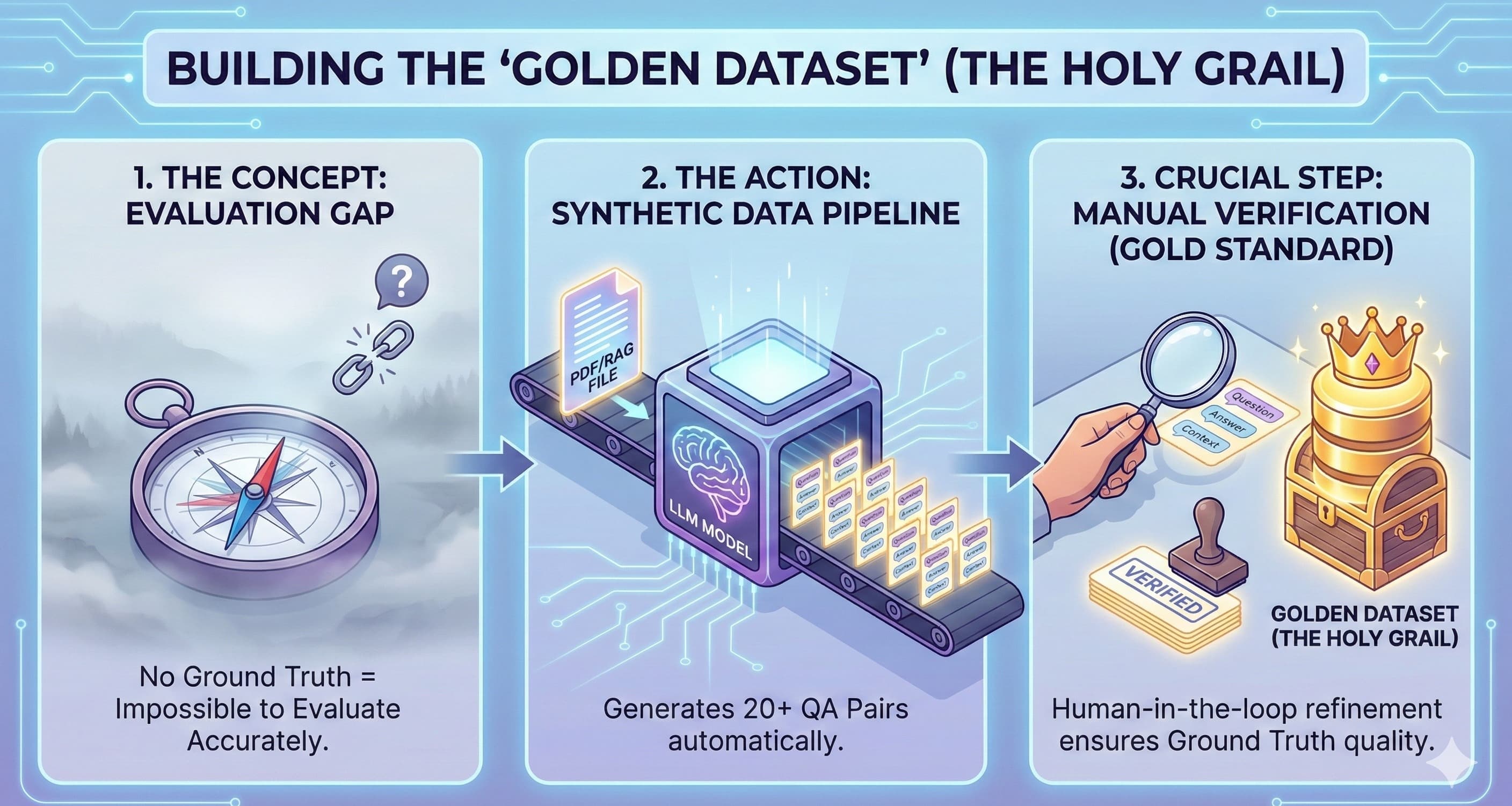
The "Notebook Phase" is the most dangerous place in AI engineering.
We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you ship it.
Three weeks later, your "production" system is hallucinating refunds, getting stuck in infinite retry loops, and burning through your monthly API budget in a single weekend.
Welcome to AI Engineering in 2026.
If 2023 was the year of the demo and 2024 was the year of RAG, 2026 is the year of Engineering Rigor. The gap between a cool prototype and a reliable system is no longer just about better prompts - it's about observability, decoupled architectures, and treating probabilistic models with the same respect we treat distributed databases.
Here is your survival guide for the modern agentic stack.
1. Escape the Monolith: The "LLM Twin" Architecture
You cannot build a reliable agentic system with a single Python script. The industry standard right now is the "LLM Twin" pattern - a microservices approach that separates your concerns into four distinct pipelines.
The Data Collection Pipeline (CDC): Stop scraping your database with nightly cron jobs. Use Change Data Capture (CDC). When a user updates their profile, that event should fire immediately. Real-time context is the only context that matters.
The Feature Pipeline (Streaming): If you need to ingest, clean, chunk, and embed data on the fly - tools like Bytewax can help here. If your embedding pipeline can't handle backpressure, your vector DB (likely Qdrant) will choke without it.
The Training Pipeline (SFT): RAG isn't enough for voice and style. You need Supervised Fine-Tuning (SFT). QLoRA adapters can be used to fine-tune specialized models cheaply, tracking every experiment with tools like Comet ML so we know exactly which dataset introduced that regression.
The Inference Pipeline: This is where the rubber meets the road. It’s not just an API call - it’s a complex orchestration of retrieval, reranking, and generation, wrapped in deep observability traces.
2. The Glass Box: Why DeepSeek Wins on Debugging
A few years ago, "Open Source vs. Proprietary" was a debate about cost. Today, it's a debate about inspectability.
If you are using GPT-5 or Claude 4.5 you are doing Black-Box Testing. You send an input, you get an output. If it fails, you guess why. Did the model drift? Did they change the system prompt? You don't know.
Enter DeepSeek-V3.x and R1.
The shift to open-weights models isn't just about saving money (though DeepSeek's training cost of $5.6M shattered our assumptions about capital efficiency). It's about White-Box Testing.
Why White-Box Matters:
DeepSeek-V3 uses a Mixture-of-Experts (MoE) architecture with 671 billion parameters, but only ~37 billion active per token. Because you have the weights, you can actually monitor Expert Utilization.
Imagine your coding agent is failing. In a black box, you're stuck. With DeepSeek, you might see that your SQL queries are being routed to the wrong experts—perhaps the "creative writing" experts instead of the "code" experts. You can see the “think” traces in R1 to audit the process, not just the output. That is a level of debugging power that proprietary APIs simply cannot offer.
3. The Horror Story: The "Zombie Worker"
The hardest thing for a traditional software engineer to grasp is that assert(x == y) is dead. You are building probabilistic systems. They are non-deterministic by nature.
Here is the failure mode keeping us up at night in 2026: The Infinite Loop.
A developer recently set up a multi-agent system where Agent A generated images and Agent B audited them. If Agent B rejected the image, it triggered a retry.
The Bug: The image generation took too long, causing a timeout. The cloud platform (Supabase) saw the timeout and "helpfully" restarted the process.
The Result: The agents didn't know they were being restarted. They entered a "Zombie" state, fighting each other in an infinite loop of creation and rejection.
The Cost: The developer burned $47,000 in hours.
The Fix: You need State Management and Circuit Breakers. You need a database (like Redis) that persists the state outside the agent's memory. If retry_count > 5, kill the process hard. Do not rely on the agent to stop itself.
4. The Mental Shift: Testing the "Thought Process"
With reasoning models like DeepSeek-R1, we've seen a new failure mode: Reasoning Variance. The model might get the right answer for the wrong reason - a "lucky guess" that will fail in production when the inputs change slightly.
The Experiment:
Don't take my word for it. Spin up a local instance of DeepSeek-R1. Run a logic puzzle 20 times at temperature 0.7
You won't just see different words; you'll see the model traversing different logical paths in the “think” block.
Engineering Rigor means validating that trace. Use LLM-as-a-Judge (with tools like Opik or any you like) to score the reasoning consistency, not just the final output string.
Conclusion
We are no longer just "prompt engineers." We are architects of probabilistic systems. The tools are here - from the decoupled pipelines of the LLM Twin to the white-box inspectability of DeepSeek. The only thing missing is the discipline to use them.
Stop shipping notebooks. Start engineering.