The RAG Triad in 2026: Testing with LLM & DeepEval
Search for a command to run...
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

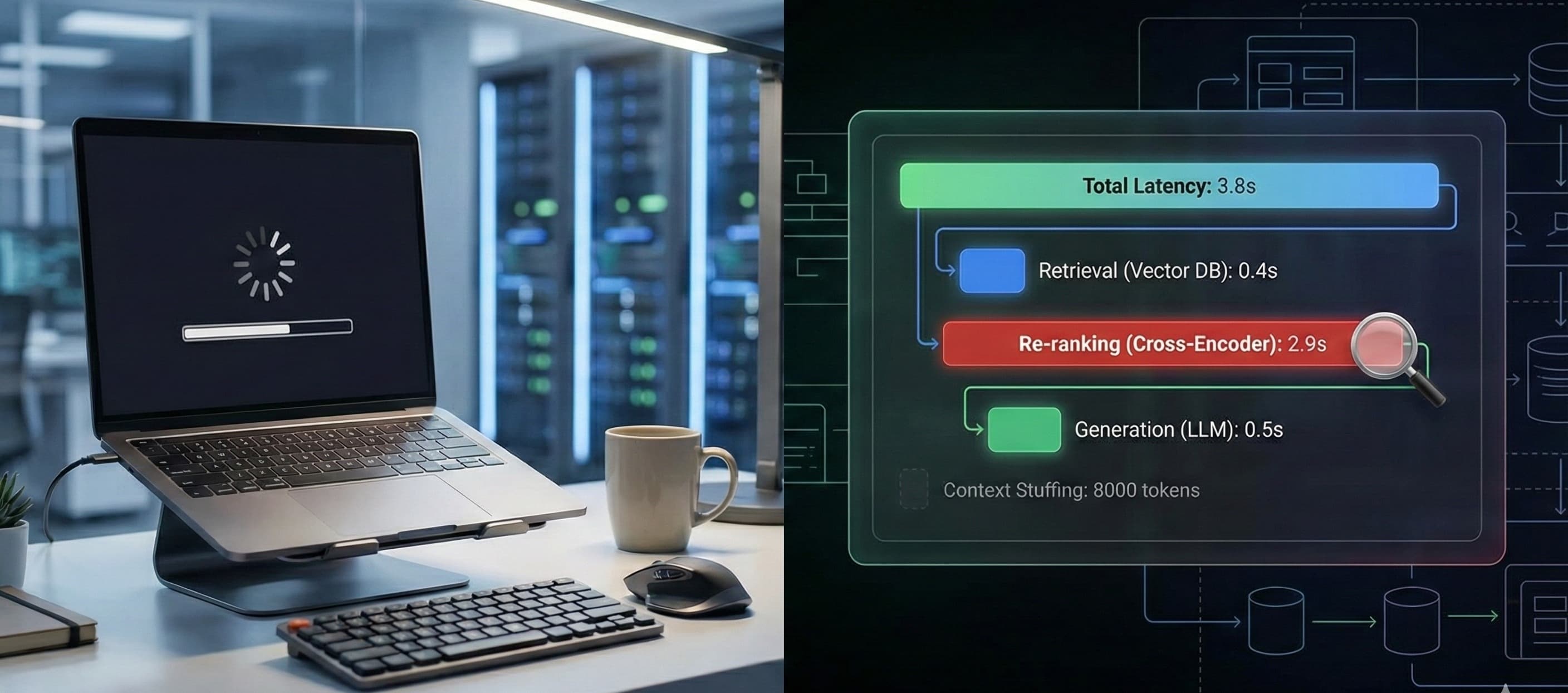
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feeds it garbage, all of them will hallucinate - or worse, confidently answer questions it shouldn't.
Check out the project here: https://github.com/iddimov/rag-sentinel
We’ve moved past the "vibe check" era of LLM development. Today, we treat prompts and retrieval as code. That means we need unit tests.
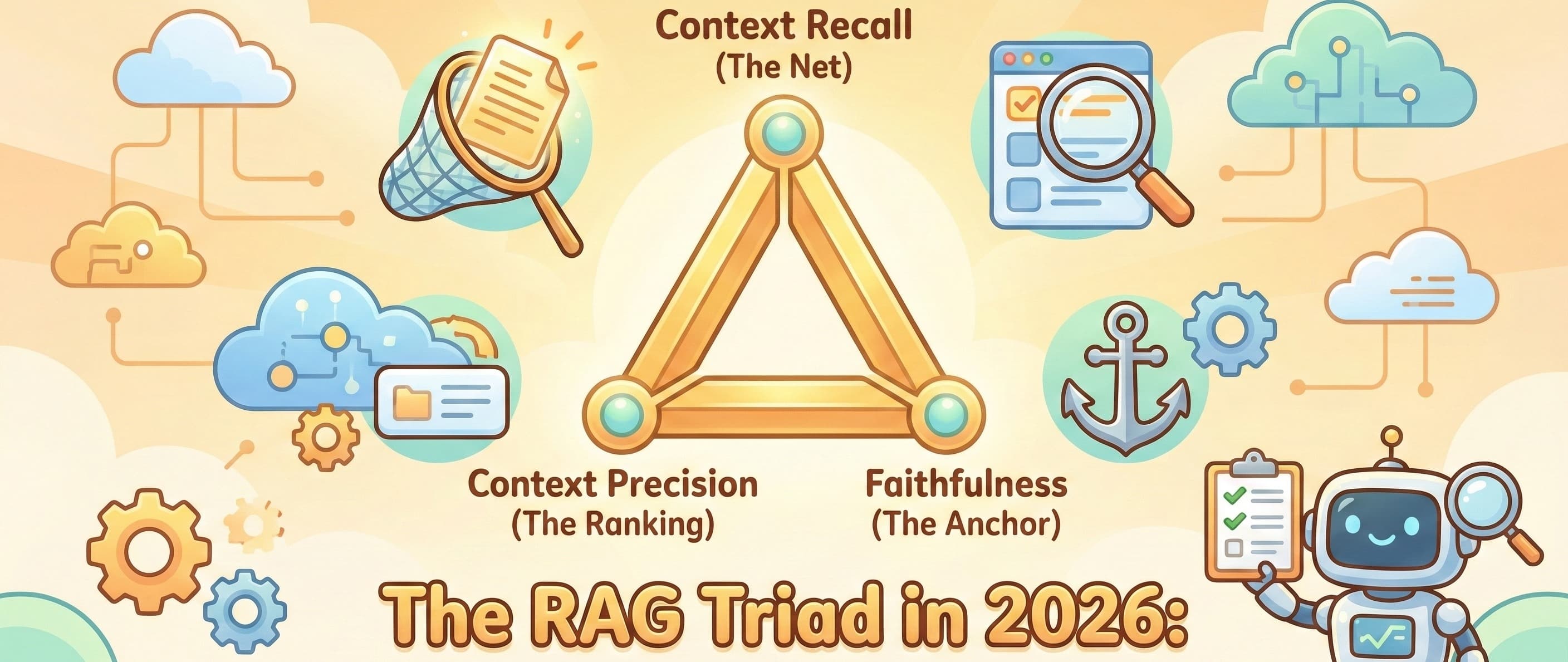
In this post, we are going to implement the "RAG Triad" - the holy trinity of RAG metrics - using DeepEval, the industry-standard framework for LLM unit testing. We will focus specifically on the tension between finding the right data and ignoring the wrong data.

Before we write code, let's clarify what we are measuring.
Context Recall ("The Net"): Did your retrieval system find the relevant chunk at all? If the answer is in document #50 but you only retrieved the top 5, your Recall is zero.
Context Precision ("The Ranking"): Is the relevant chunk at the top? If the answer is in chunk #1, your precision is perfect. If it's in chunk #5 (buried under 4 irrelevant chunks), your precision drops.
Faithfulness ("The Anchor"): Is the LLM's answer derived solely from the retrieved context? This is your hallucination safety net.
We will use DeepEval because it integrates natively with pytest, allowing you to run LLM evals right alongside your backend tests.
High recall with low precision is dangerous - it means you are flooding GPT-5/DeepSeek/Gemini with noise, increasing latency and cost. High precision with low recall is useless - you are missing the answer entirely.
Here is how to test for both.
Python
import pytest
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import ContextualPrecisionMetric, ContextualRecallMetric
# We use GPT-5 as the judge for our metrics
MODEL = "gpt-5"
def test_retrieval_quality():
# 1. The Scenario
# User asks about "Project Manhattan"
input_prompt = "Who was the lead physicist on the Manhattan Project?"
expected_output = "J. Robert Oppenheimer"
# 2. The Retrieval Simulation
# Ideally, our retriever fetches relevant chunks.
# Let's simulate a case where the answer is retrieved but buried (Rank 3).
retrieved_context = [
"The Manhattan Project cost $2 billion.", # Irrelevant
"Los Alamos was the primary site.", # Irrelevant
"J. Robert Oppenheimer led the Los Alamos laboratory.", # RELEVANT (Buried)
"Trinity was the code name of the first test." # Irrelevant
]
test_case = LLMTestCase(
input=input_prompt,
actual_output="J. Robert Oppenheimer", # What our RAG generated
expected_output=expected_output, # The ground truth
retrieval_context=retrieved_context
)
# 3. The Metrics
# Thresholds are strict: we want high recall (found it) and high precision (ranked it).
recall_metric = ContextualRecallMetric(
threshold=0.7,
model=MODEL,
include_reason=True
)
precision_metric = ContextualPrecisionMetric(
threshold=0.5, # Lower threshold because it was rank 3, not rank 1
model=MODEL,
include_reason=True
)
# 4. The Assertion
assert_test(test_case, [recall_metric, precision_metric])
If you run this test, Context Recall will pass (the answer is in the list). However, Context Precision will be lower than 1.0 because the relevant chunk wasn't at the top. This tells you your re-ranker needs work, even if your retriever is fine.
This is the most critical test for production RAG systems. We are going to intentionally feed GPT-5/DeepSeek/Gemini irrelevant "poison" and assert that it ignores it.
If we ask about the moon, and the context talks about cheese, GPT-5 should answer based only on factual reality (or refuse to answer), depending on your system prompt. But specifically for Faithfulness, we want to ensure the model doesn't hallucinate an answer from the bad context.
Python
from deepeval.metrics import FaithfulnessMetric
def test_poisoned_context_handling():
# 1. The Poison Scenario
input_prompt = "What is the capital of France?"
# We inject POISON into the context.
# Completely irrelevant information.
poisoned_context = [
"The capital of Mars is Elon City.",
"France is known for good cheese.",
"Paris is a character in Romeo and Juliet."
]
# The Model's Response
# A robust RAG system might ignore the context and use internal knowledge,
# OR answer "I don't know" if restricted to context.
# Let's assume our system is allowed to use internal knowledge if context is bad.
actual_output = "The capital of France is Paris."
test_case = LLMTestCase(
input=input_prompt,
actual_output=actual_output,
retrieval_context=poisoned_context
)
# 2. The Metric: Faithfulness
# Faithfulness checks: "Is the answer supported by the context?"
# Since 'Paris is capital' is NOT in our poisoned context,
# a standard Faithfulness check should actually FAIL (score 0).
# This is GOOD. It proves the model ignored the context.
metric = FaithfulnessMetric(
threshold=0.5,
model=MODEL,
include_reason=True
)
metric.measure(test_case)
# 3. The Negative Assertion
# We expect Faithfulness to be LOW because the model used internal knowledge
# instead of the (poisoned) context.
print(f"Faithfulness Reason: {metric.reason}")
# If the model had said "The capital of France is Elon City",
# Faithfulness would be HIGH (1.0), but the answer would be wrong.
# For this specific 'Robustness' test, we actually want to assert
# that the model was NOT faithful to the poison.
assert metric.score < 0.5, "Model fell for the trap and used poisoned context!"
Note: In a strict RAG system where the prompt is "Answer ONLY using the provided context", the correct behavior would be for the model to output "I cannot answer from the context." In that case, you would test for an exact string match of the refusal.
LLM nowadays is smarter, but that doesn't make your RAG pipeline immune to failure. By splitting your metrics into Retrieval(Precision/Recall) and Generation (Faithfulness), you can pinpoint exactly where the break happens.
Low Recall? Fix your embeddings or chunking strategy.
Low Precision? Add a re-ranker (like Cohere or BGE).
Low Faithfulness? Adjust your system prompt temperature or penalize the model for hallucinating outside the context.