The Death of the Flaky Test: Why I Stopped Writing Scripts and Started Architecting Agents

Search for a command to run...
No comments yet. Be the first to comment.
It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

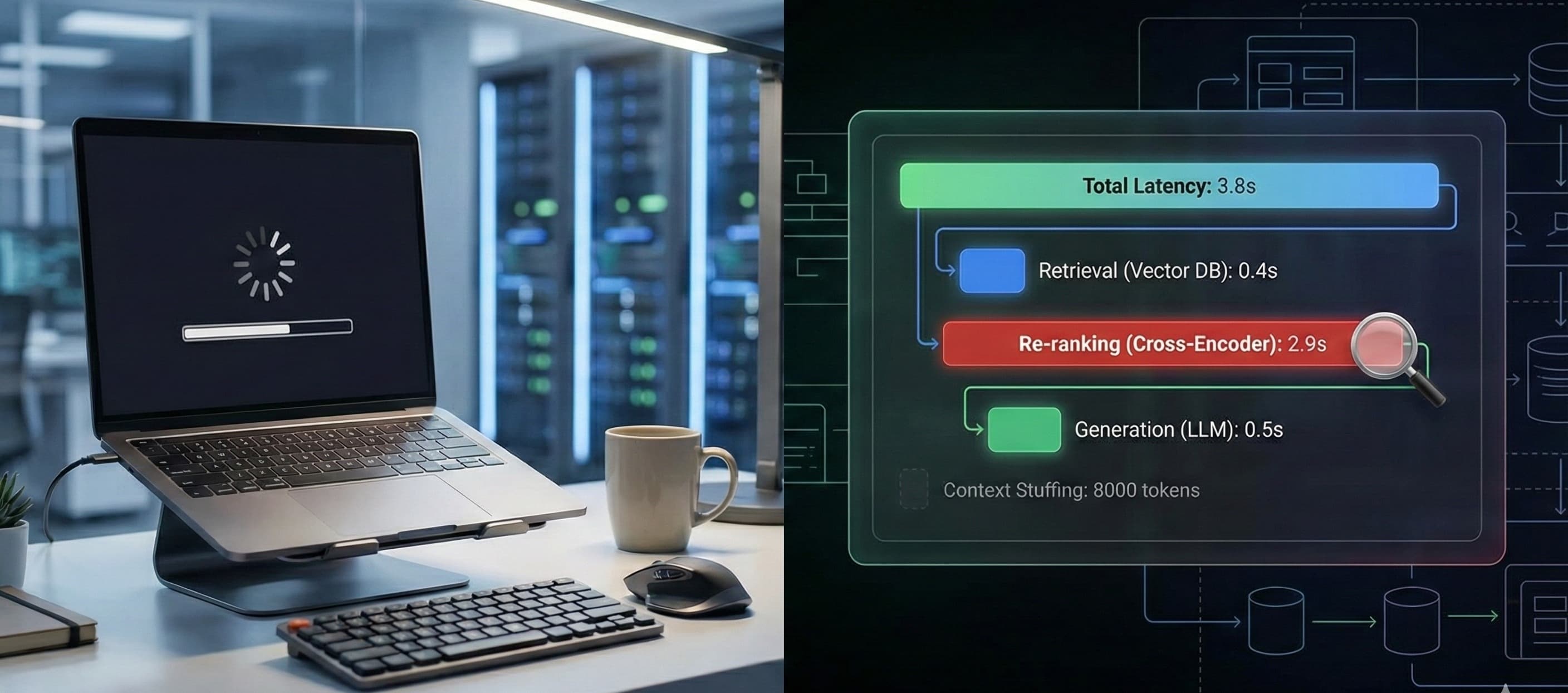
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
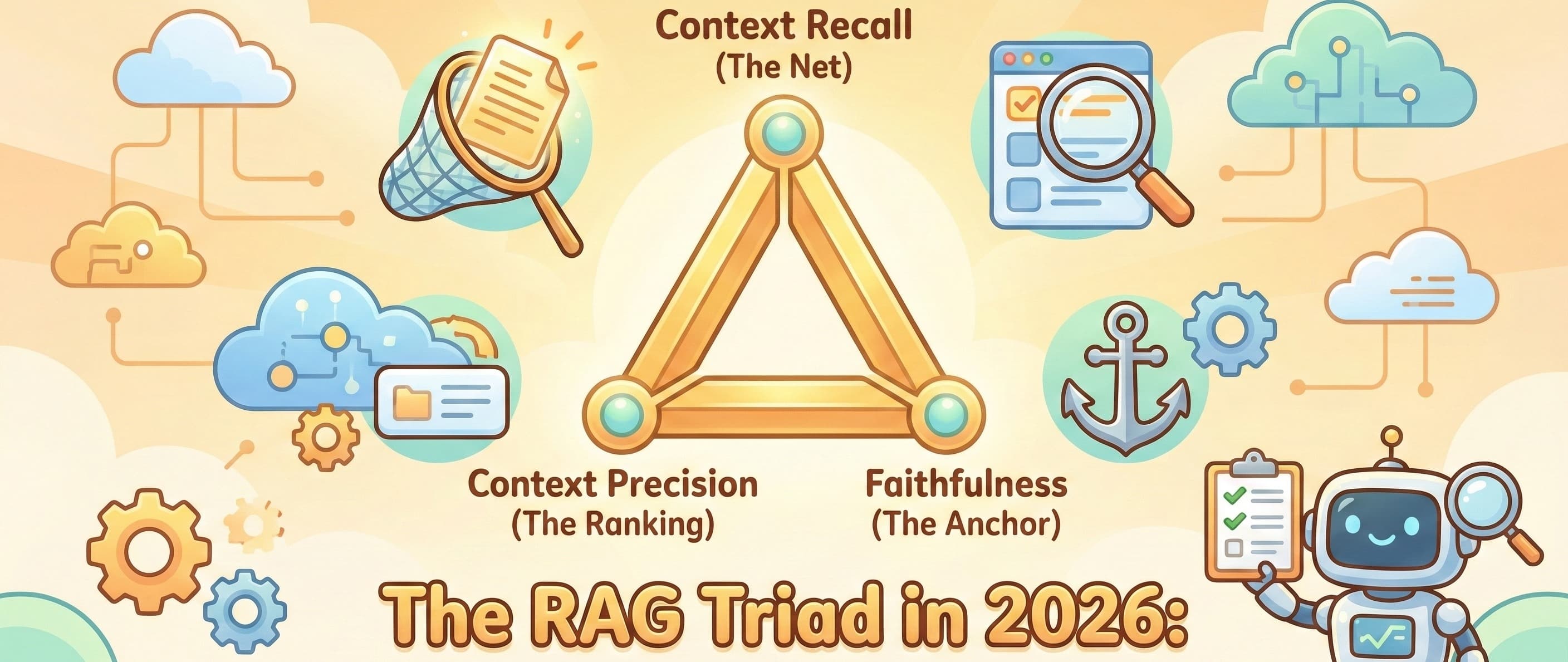
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong.
For the last decade, we’ve been stuck in a loop of "write, break, fix, repeat." We called it "Automation," but it felt a lot more like babysitting. We built fragile Rube Goldberg machines that screamed every time a developer changed a class name.
Check out the project here: https://github.com/iddimov/llm-playwright

I recently spent some time digging into the LLM-Playwright Automation Framework, an open-source project that finally feels like the exit ramp from this maintenance hell. It’s not just another wrapper around Selenium. It’s a glimpse into the actual future of Quality Engineering - where we stop writing scripts and start architecting Agentic Systems.
Here is the gap analysis of why the old way is dying, and a look at the tech stack - specifically the Planner-Generator-Healer pattern - that is replacing it.
The fundamental flaw of traditional automation (Selenium, Cypress, and yes, vanilla Playwright) is that it is context-blind. A script doesn't know what a login button is; it only knows that it’s looking for #btn-primary-login. If that ID changes, the script fails. It has no eyes, no intuition, and no ability to adapt.
We tried to fix this with "Self-Healing" tools in 2024, but most were just glorified try-catch blocks with a dictionary of backup selectors.
The shift to Agentic Engineering changes the primitive. We aren't giving the computer a list of steps anymore. We are giving it sight via the Model Context Protocol (MCP) and a brain via reasoning models like OpenAI’s o1 or DeepSeek’s R1.
mcp-useThis project is built on a stack that I think will be the standard for 2026: Node.js, TypeScript, LangChain, and most importantly, MCP.
If you haven't touched MCP (Model Context Protocol) yet, think of it as the USB-C for AI. Before MCP, connecting an LLM to a browser was a mess of ad-hoc function calling and prompt injection. You had to paste the HTML into the prompt and pray the token limit didn't cut you off.
With MCP, the browser becomes a Server. It exposes its accessibility tree, network logs, and console as structured Resources. The Agent is the Client.
This framework uses a library called mcp-use to bridge the gap. It’s a unified client for Node.js that handles the messy handshake between your LLM and the tool.
Here is why this matters: Security and Stability. Instead of giving an agent raw eval() access to your browser (terrifying), mcp-use creates a strict contract. The agent can only "click," "fill," or "navigate" because those are the only tools the MCP Server exposes.
// A glimpse of how clean the mcp-use integration is
import { MCPAgent, MCPClient } from 'mcp-use';
const client = MCPClient.fromDict({
mcpServers: {
playwright: {
command: 'npx',
args: ['@playwright/mcp-server']
}
}
});
This simple setup allows the agent to "see" the page the way a human does - by semantic meaning ("the button that says 'Checkout'"), not by arbitrary DOM structure.
The brilliance of this framework isn't just the tools; it's the Multi-Agent Architecture. It breaks the testing lifecycle into three distinct personas. This is the "Mixture of Experts" pattern applied to QA.
Model: High-reasoning (OpenAI o1 or DeepSeek R1).
Job: Strategy.
Input: "Test the checkout flow."
The Planner doesn't write code. It explores. It browses the app, clicks around, and maps the territory. It handles the cognitive load that used to burn us out: finding the edge cases. It outputs a structured Markdown plan (specs/coverage.plan.md) that details what needs to be tested, covering happy paths and negative scenarios.
Model: High-coding capability (GPT-4o or DeepSeek V4).
Job: Execution.
Input: The Planner's Markdown.
This agent takes the plan and writes the Playwright code. But it doesn't just spit out spaghetti code. It adheres to the Page Object Model (POM). It creates strictly typed TypeScript files in pages/ and tests/. It treats test code as production code.
Model: Fast & Cheap (Llama 3 or DeepSeek V3).
Job: Resilience.
Input: A failed test report.
This is the killer feature. When a test fails, the Healer wakes up. It reads the Playwright trace, looks at the error (e.g., "Element not found"), and looks at the current DOM via MCP.
It realizes, "Oh, the dev changed the button ID from #submit to #complete-order, but it's still the same button." It updates the selector in the code, runs the test again, and if it passes, it commits the fix. Zero human intervention.
"But isn't this expensive?"
In 2023, maybe. In 2026, no.
The cost of running a Planner agent to generate a suite might be $2.00 in tokens (depends on the model used 😏). The cost of an SDET spending 4 hours writing that same suite is slightly more…
Furthermore, we have Context Compaction. We don't feed the entire history to every agent. The Generator only sees the Plan, not the Planner's internal monologue. We use Prompt Caching to cache the system instructions (the "How to write Playwright" rules), so we only pay for the new logic.
And let's talk about DeepSeek. The framework supports it natively. Using DeepSeek V4 for the heavy code generation cuts costs by nearly an order of magnitude compared to GPT-5 class models, without losing accuracy on syntax.
This isn't just a cool repo; it's a new operating model.
The LLM-Playwright Automation Framework demonstrates that we are moving toward a world where humans define the Intent ("Ensure the user can pay"), and the AI handles the Implementation (Selectors, waits, retries).
If you are an engineer, your job is shifting. You are no longer a script writer. You are an Agent Architect. You define the constraints, the tools, and the goals. The agents do the clicking.
Stop fixing flaky tests. Let the robots do it.