The Evaluation Bottleneck: Building a "Golden Dataset" Without Losing Your Mind
Search for a command to run...
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

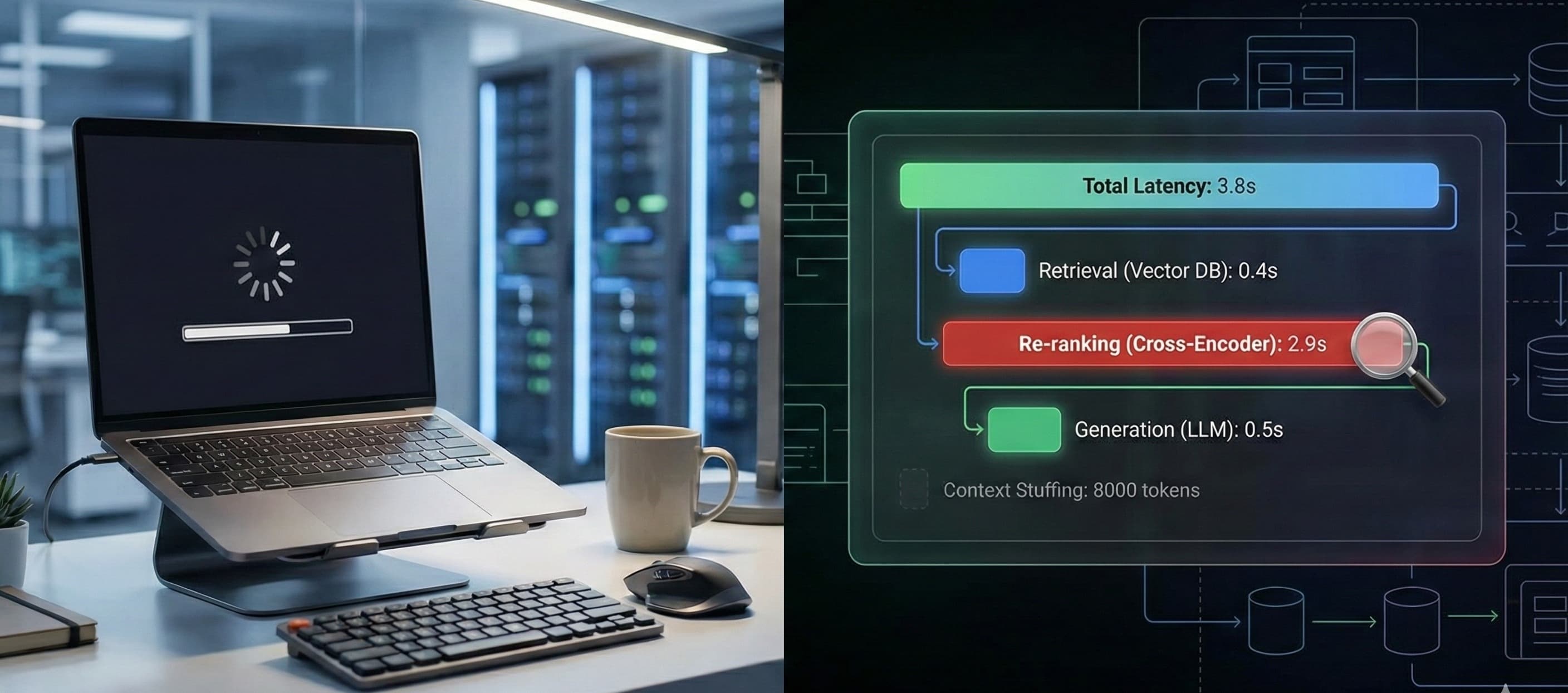
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
If I see one more "vibe check" evaluation in a pull request, I’m going to scream.
You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a specific edge case in your documentation, and your RAG pipeline confidently hallucinates an answer that doesn't exist.
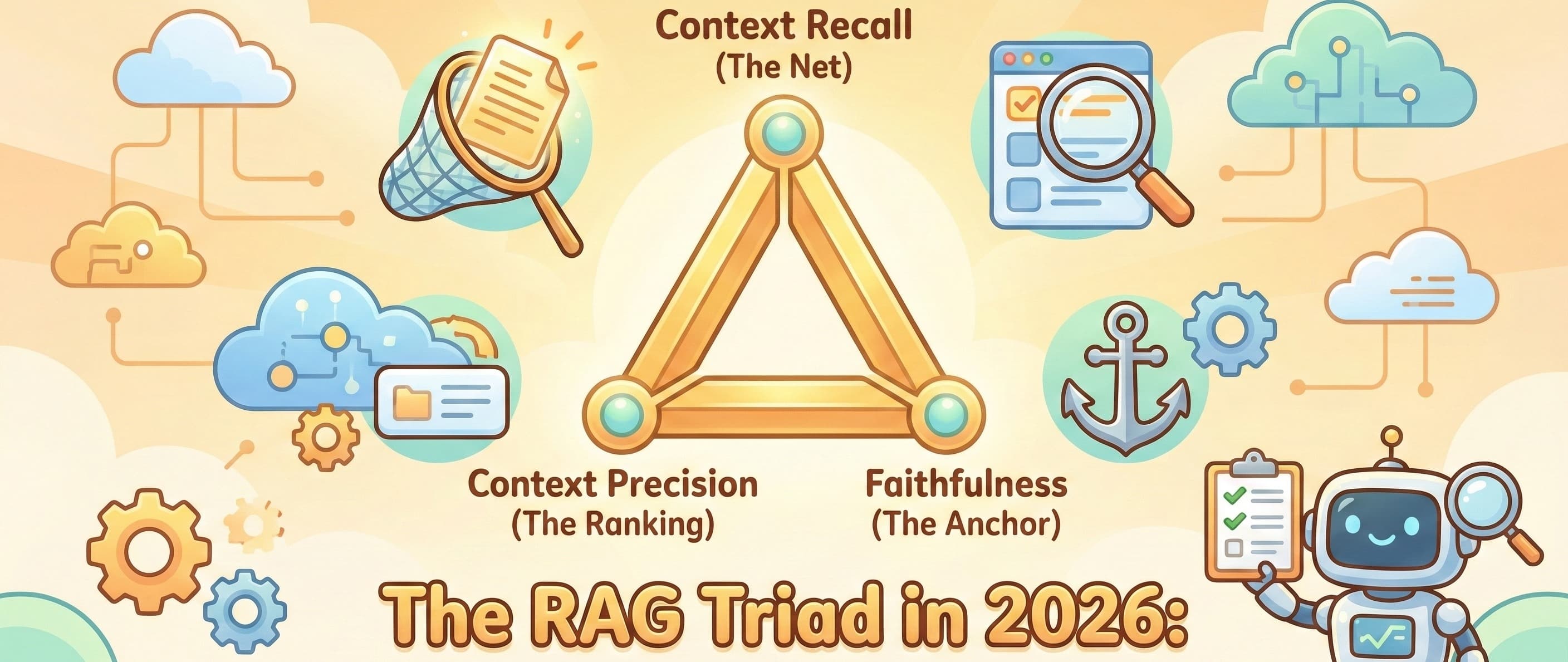
We cannot engineer systems based on vibes. We need metrics. But here is the hard truth that stops most teams dead in their tracks: You cannot calculate metrics without Ground Truth.
You can't score Recall if you don't know what the right answer was supposed to be. You can't score Hallucination if you don't have a factual reference.
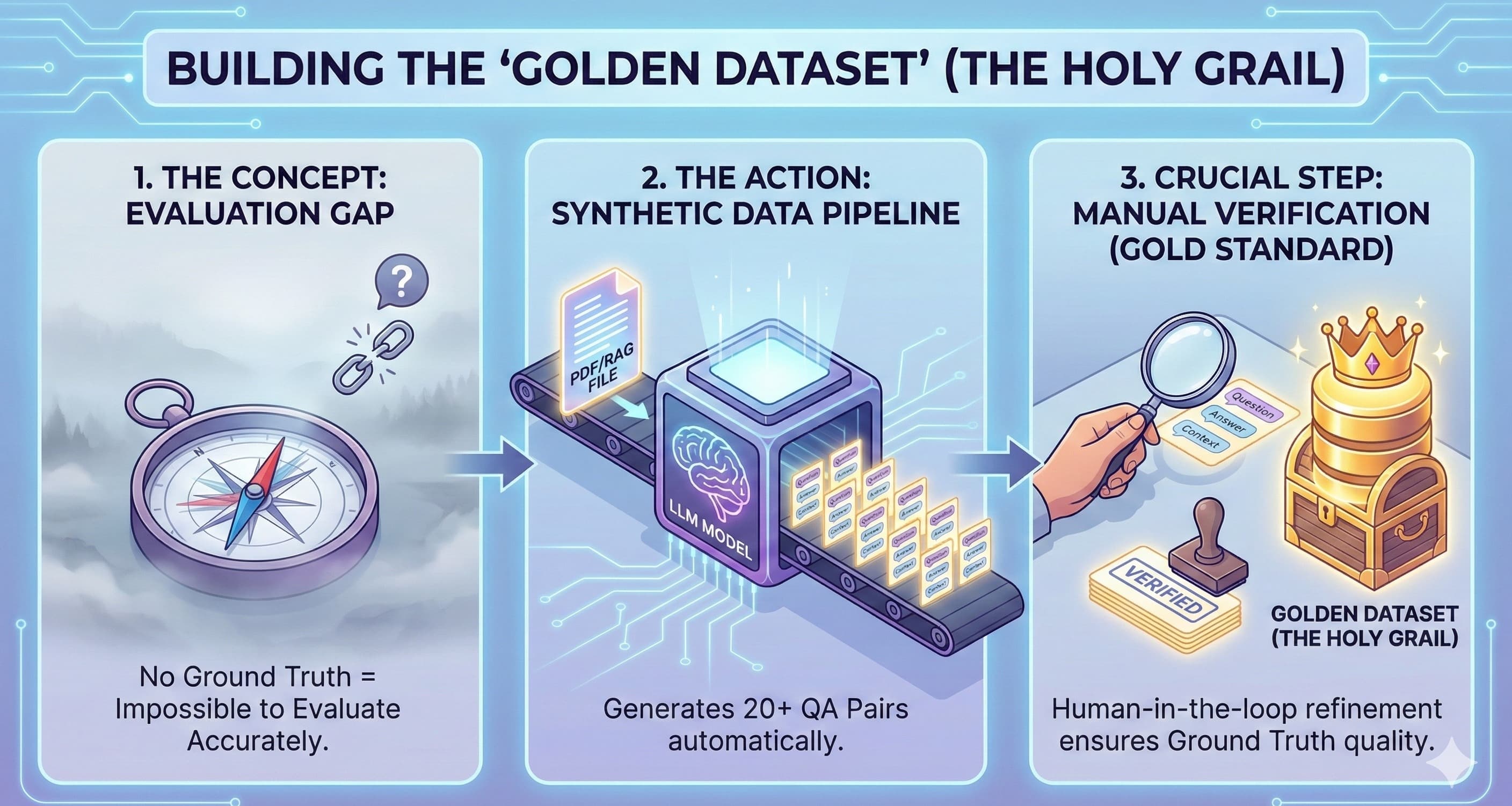
Today, we are solving the biggest bottleneck in LLM Test Automation: building the Golden Dataset (the Holy Grail) without spending three weeks typing into a spreadsheet. We’re building a Synthetic Data Factory.
Most people try to automate 100% of this and end up with garbage questions like "What is the title of the document?". That’s useless.
We are going to use a Human-in-the-Loop approach.
Ingest: Parse complex docs (tables and all).
Generate: Use a reasoning model (Claude 4.5 Sonnet, GPT-5 or any other LLM model) to create complex QA pairs.
Verify (The Crucial Step): Manually audit a small "Seed Set" (20 pairs).
Scale: Use those 20 perfect pairs to generate 500 more.
Don't overcomplicate this.
Parsing: LlamaParse (Standard PDF parsers turn tables into soup. Don't use them.)
Generator Model: Claude 4.5 Sonnet or GPT-5 (We need high instruction adherence).
Structure: Pydantic (Forcing JSON output is non-negotiable).
If you feed your generator raw text from PyPDF that has mashed headers and footers into the middle of sentences, your Golden Dataset will be hallucinations.
We need semantic context.
Python
# Simple setup using LlamaIndex or similar wrapper
from llama_parse import LlamaParse
parser = LlamaParse(
result_type="markdown", # Markdown preserves structure better than plain text!
api_key="llx-..."
)
# This actually respects tables and headers
documents = parser.load_data("./technical_spec_v2.pdf")
Pro-tip: Always inspect the markdown output before moving to the next step. If the parser missed the pricing table, your evaluation will fail on pricing questions.
We aren't just asking the LLM to "generate questions." We need a specific schema. We need the Question, the Ground Truth Answer, and the Context (the snippet of text where the answer was found).
We define this structure strictly using Pydantic.
Python
This is where you win or lose. Do not ask for generic questions. Ask for "Multi-hop" reasoning.
System Prompt: "You are a QA Lead for a technical product. Your goal is to break the retrieval system. Generate 20 QA pairs based on the provided text.
Rules:
Include at least 5 questions that require reading a table.
Include 3 questions about what the document does NOT contain (Negative constraints).
The 'Answer' must be factual and explicitly supported by the 'context_snippet'."
This is the part everyone skips, and it’s why their eval pipelines fail.
You just generated 20 pairs. Stop. Do not generate 100 more yet.
You need to act as the "Teacher."
Open the JSON/CSV.
Read the context_snippet. Does it actually contain the answer?
Is the answer 100% correct?
Is the question actually hard? (If it's just "What is the date?", delete it).
Why do we do this? Because LLMs are people-pleasers. They might generate a question for a section of text that is actually irrelevant. If you use bad data to test your RAG app, you are essentially grading a math test with a broken calculator.
This manual verification of 20 pairs gives you your Few-Shot Examples.
Once you have your verified 20 pairs, you don't need to manually write anymore. You now feed those 20 perfect examples back into the prompt as "Few-Shot" context.
"Here are 20 examples of perfect QA pairs."
"Generate 100 more following this exact style and logic depth."
Now, the LLM mimics your high standards. It mimics the difficulty curve you curated. You’ve effectively cloned your own QA capability.
Building a Golden Dataset isn't the flashy part of AI engineering. It’s the janitorial work. But once you have this golden_dataset.json, everything changes.
You can run ragas or DeepEval in your CI/CD pipeline.
You catch regressions before they hit prod.
You can finally prove to your boss that the new model is actually better, not just "vibes" better.
Stop guessing. Build the dataset. It takes one hour, and it saves you hundreds of hours of debugging later.