The Real Work Begins When You Deploy
Remember that feeling of success? The moment your Large Language Model (LLM) application passed all its internal tests, delivered impressive results in the sandbox, and finally got the green light for production. It’s a huge milestone, a testament to countless hours of data wrangling, prompt engineering, and model fine-tuning.
But here’s a hard-earned lesson from someone who’s managed these systems in the real world: launching an LLM isn't the finish line; it’s the start…
The perfectly behaved model you spent months perfecting can, and often will, start to behave differently once it hits the wild, unpredictable world of real users. Unlike traditional software that usually works or breaks with a clear error message, LLMs can degrade silently. They might become less helpful, less relevant, or subtly introduce biases, all without a loud crash.
This isn't a cause for alarm; it's a call for preparation. This post is your pragmatic guide to moving beyond pre-launch testing and building a robust system to monitor, manage, and maintain your LLM's quality and relevance. We'll explore the hidden pitfalls, equip you with an essential toolkit, and outline strategies to keep your application performing at its peak, long after that initial launch fanfare fades.
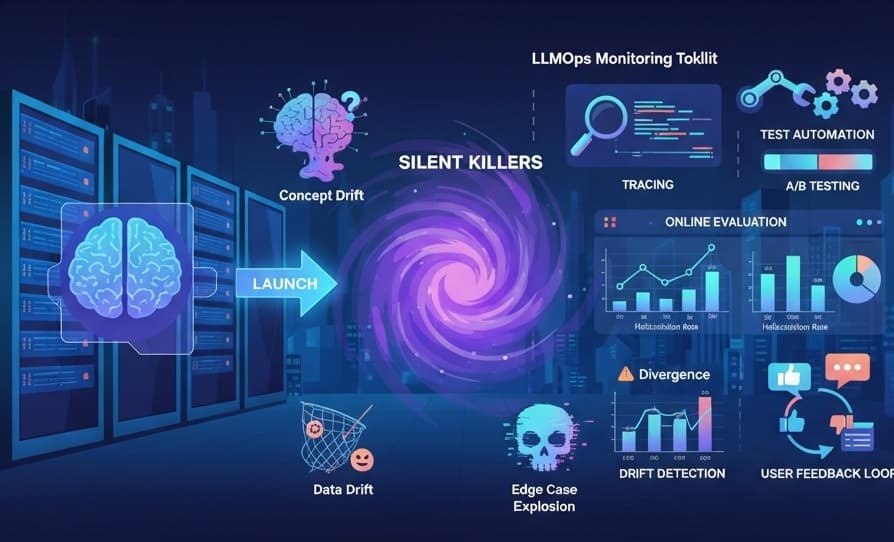
The Silent Drifts: Why Production LLMs Can Lose Their Edge 📉

Before we can build robust solutions, we need to understand the underlying challenges. In production, your LLM is subject to subtle forces that can quietly erode its effectiveness over time.
Data Drift: The Moving Target. This is arguably the most common and intricate challenge. The universe of user prompts your model encounters in production rarely stays static. Imagine a meticulously trained customer service bot designed for polite, formal inquiries suddenly inundated with casual slang, emojis, or different cultural contexts from real users. The live data simply starts to diverge from the data it was trained on, making its carefully learned patterns less effective.
Concept Drift: When the World Changes. Sometimes, it’s not just the inputs that change, but the very meaning of the concepts the model is dealing with. A news summarizer's understanding of "geopolitical stability" might need to adapt quickly after a major global event. The model's internal representation of the world no longer matches the evolving external reality, making its responses outdated or irrelevant.
Edge Case Explosion: The Unforeseen Chaos. Your internal testing might cover thousands, even tens of thousands, of scenarios. But production traffic will hit you with millions. This is where you’ll discover bizarre, unexpected prompt structures, user inputs you never imagined, or interactions that push your model into truly uncharted and unhelpful territory. It's the ultimate stress test.
To address these challenges effectively, you need a central command center for your operations. Your monitoring stack should be built on three critical pillars.
1. Tracing: The Diagnostic Record for Every Interaction
If "something went wrong," tracing is your foundational layer for understanding exactly what. Think of it as a detailed flight recorder for every single request and response your LLM application processes.
What to Log Religiously:
The complete user prompt (input).
The final LLM response (output).
Any intermediate steps, especially if you're using agents, RAG (Retrieval Augmented Generation) systems, or tool-use. This includes internal prompts, API calls made, and the results of those calls.
The precise model version, specific prompt template, and any configuration parameters used for that particular interaction.
Latency at each step and total end-to-end response time.
Why It's Critical: When a customer reports, "Your bot gave me a strange answer about my account!", tracing is your only way to perfectly reconstruct that exact interaction. You can see the input, every internal step, and the final output, allowing for precise diagnosis rather than guesswork.
Offline evaluations are great for pre-deployment checks, but production demands real-time awareness. You need to continuously measure your LLM's quality and operational health against live traffic.
3. Drift Detection: The Early Warning System 🚨
This is your proactive approach to managing model relevance. Instead of waiting for users to complain, you're constantly looking for signals that your LLM is entering uncharted territory.
How It Works: The core idea is to convert your prompts and responses into numerical representations called embeddings. These embeddings capture the semantic meaning. You then continuously compare the statistical distribution of these new, live embeddings to a "golden set" from your training or carefully curated validation data.
What You're Looking For: A significant change in this distribution (e.g., measured using metrics like Kullback-Leibler (KL) divergence or Jensen-Shannon distance) is your early warning. If the new prompts look statistically very different from what your model was trained on, it's a strong sign of data drift. Your model is operating in unfamiliar territory and might be performing poorly, even if it hasn't outright "failed." This could trigger an alert that your model might need retraining, prompt adjustments, or an urgent human review.
Closing the Loop: Turning User Feedback into Fuel 🔄
Your users aren't just consumers of your LLM; they are, hands down, your most effective and comprehensive quality assurance team. You need a frictionless system to capture their invaluable feedback and, crucially, to make that feedback actionable.
Advanced Tactics: Automation, Scale, and Continuous Improvement 🤖
Once you’ve got the fundamentals down, it’s time to lean into automation and scalability. This is where your LLM operations truly become resilient and efficient.
Automated Regression Testing (Beyond the Golden Set): Expand this. Before deploying any change – a new prompt, a different model, an updated RAG source – automatically run a comprehensive suite of tests against your full curated dataset of challenging cases. This acts as your final gate, preventing known issues from creeping back in.
Canary Deployments & A/B Testing: Your Safe Rollout Strategy. Never deploy a new model or major prompt change to 100% of your users at once. Instead, adopt a canary deployment strategy:
Route a tiny fraction of your traffic (e.g., 1-5%) to the new version.
Closely monitor its live operational metrics (latency, cost, error rate) and, crucially, its LLM quality metrics (feedback scores, hallucination rates) against the existing version.
If the new version performs well, slowly increase the traffic it receives. If it falters, immediately roll back. This mitigates risk and provides real-world performance data before full deployment.
Smart Alerting: Go Beyond the Basics. Don't just alert if a server crashes. Set up intelligent alerts for your key LLM-specific metrics.
ALERT if average Hallucination Score > 0.15 for more than 1 hour.
ALERT if LLM Latency (P95) > 5 seconds for more than 30 minutes.
ALERT if user "Thumbs Down" rate increases by 20% in an hour. These alerts ensure you're notified of performance degradation before it becomes a widespread user complaint.
Conclusion: The Journey of Continuous Quality
Managing an LLM in production is not a "set it and forget it" task. It's a dynamic, continuous journey of monitoring, learning, and adaptation. The real value of your LLM application isn't just its initial brilliance; it's its sustained, reliable performance over time.
By embracing a robust monitoring toolkit, meticulously tracing interactions, proactively detecting drift, creating a tight feedback loop with your users, and intelligently automating your testing and deployment processes, you'll move beyond anxiously reacting to problems. Instead, you'll be able to proactively maintain a high-quality, reliable, and genuinely effective AI application that truly serves your users and your business goals for the long haul.
The lab is where innovation begins, but production is where real value is delivered. Let's make sure our LLMs thrive there.