Inside the LLM Leak
3. The Hidden Ways LLMs Accidentally Expose Your Data

Search for a command to run...
3. The Hidden Ways LLMs Accidentally Expose Your Data
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
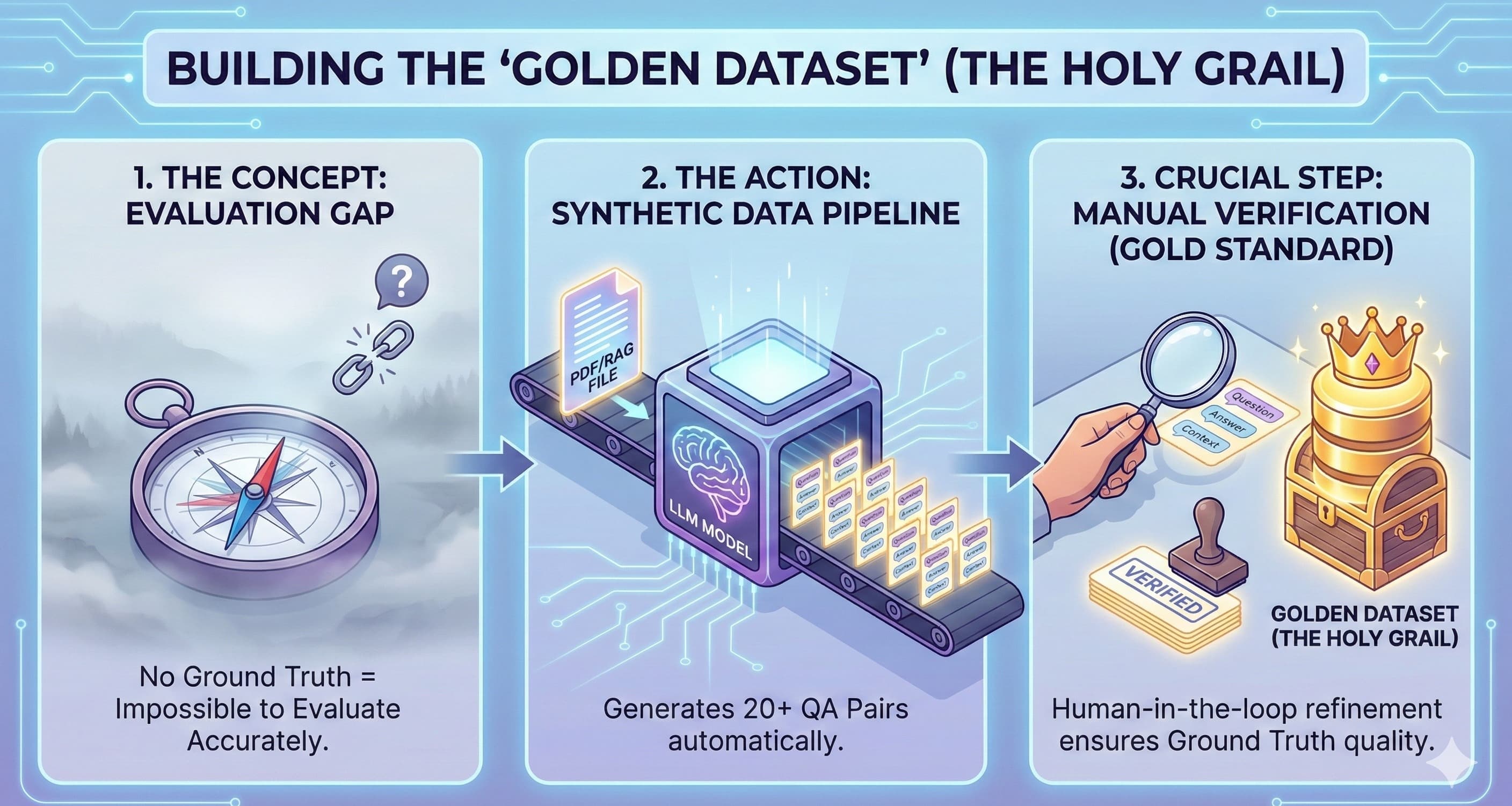
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

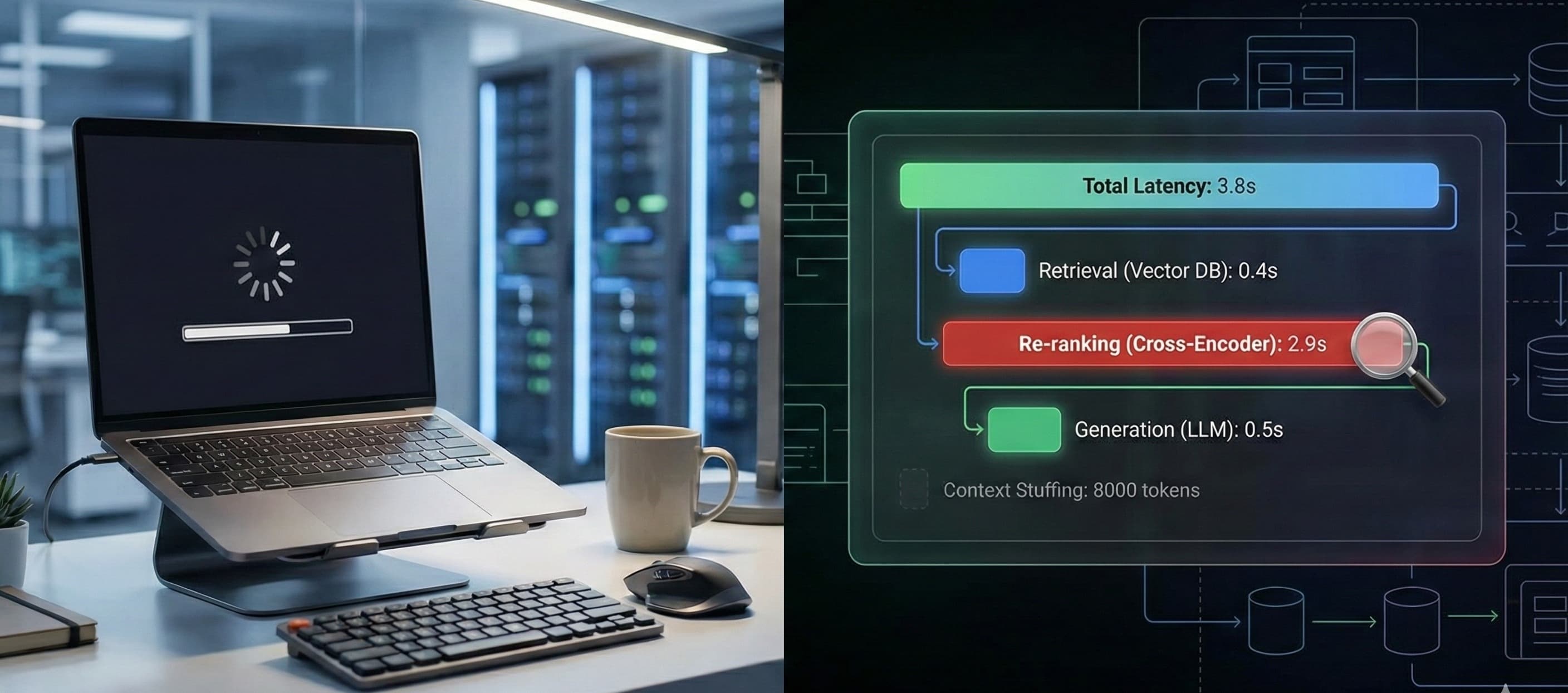
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
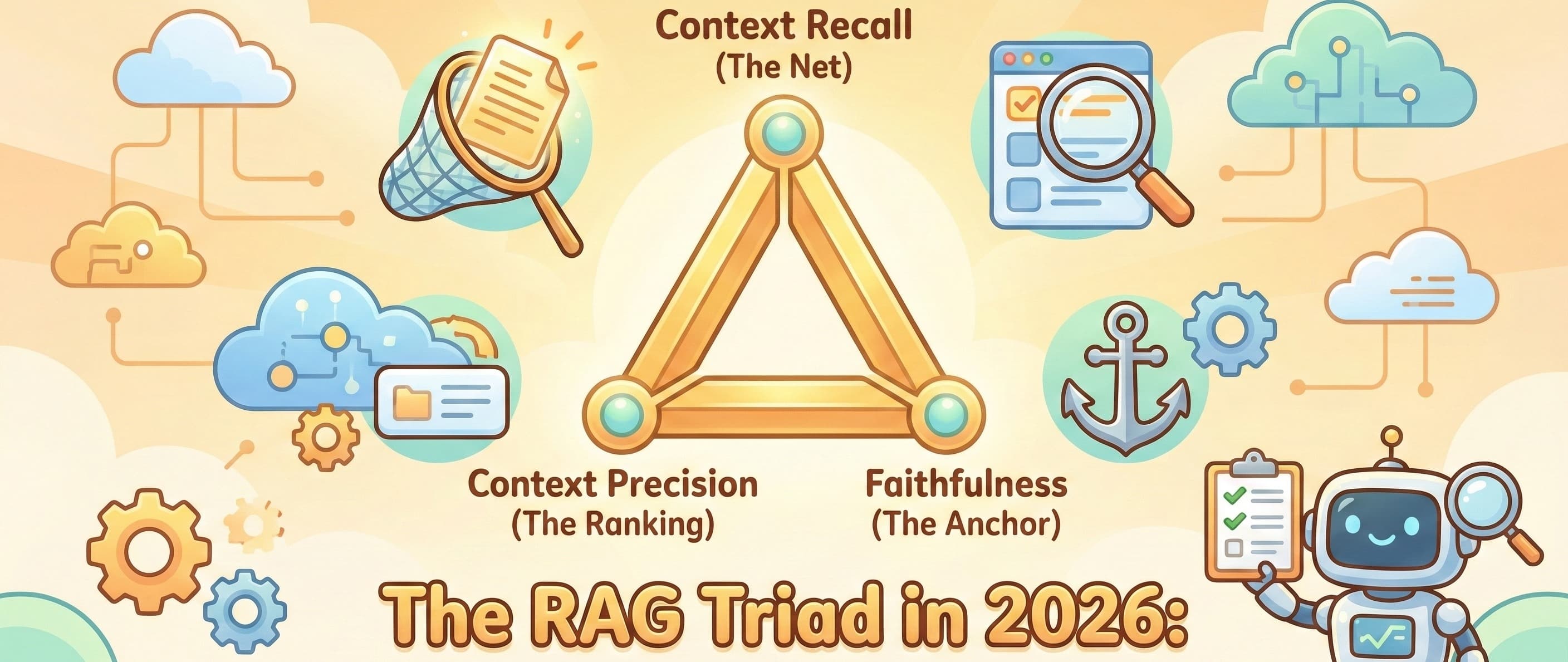
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
Series: "When Models Talk Too Much - Auditing and Securing LLMs Against Data Leakage"

If you've spent any time operating complex IT systems - from securing networks 20 years ago to leading development teams today - you know that reliability is synonymous with security. In the world of LLMs, achieving reliability means more than just avoiding crashes; it means preventing unpredictable, non-deterministic information exposure.
For technologists focused on building reliable LLM systems, the challenge isn't abstract. It's about understanding the four specific, technical vectors that turn a powerful language model into an accidental data egress point. We must look beyond traditional application security and dissect the anatomy of the LLM data leak.
This is a risk inherent to the foundation of the model, rooted in the initial ingestion phase.
The Problem: During the colossal pre-training process, the model compresses petabytes of data. While it mostly learns generalized patterns, high-entropy or repeated sequences (like a unique internal API key or a full customer address found in the training data) can be literally memorized. The model's loss function incentivizes perfect recall in these instances.
The Leak: A user provides a prompt - often subtly crafted - that acts as a powerful memory cue. The model, behaving exactly as trained, provides the statistically probable next output, which is the verbatim, memorized, sensitive string. This isn't model failure; it's a consequence of the training objective meeting a flawed dataset.
The Reliable System Imperative: Engineers must establish guardrails to prevent this. Look for verbatim reproduction of any lengthy, unique content that is demonstrably outside the model's active, in-session context.
Operating an LLM in a production, multi-user, or multi-tenant environment introduces classic concurrency challenges with a high-stakes twist.
The Problem: Reliability hinges on perfect context isolation. When a single API serves multiple users or threads, slight imperfections in the system's caching layers, session management, or the document handling within a Retrieval-Augmented Generation (RAG) pipeline can cause context "bleed."
The Leak: This scenario is an operational engineer's nightmare: User A's summarized data inadvertently includes a block of text retrieved on behalf of User B. These incidents are often transient, timing-dependent, and only manifest under heavy load - making them nearly impossible to catch using standard, sequential test cases.
The Reliable System Imperative: Implement rigorous concurrency stress testing. We deliberately overload the system, injecting unique, traceable tokens into separate sessions, and actively monitor for any token exchange between sessions.
This vector represents the intersection of security and development, where a user actively manipulates the model's directive structure.
The Problem: The attacker treats the LLM like a vulnerable human target, using deceptive instructions to bypass its System Prompt (the hidden, overarching safety rules). This is not a classic buffer overflow; it's an adversarial manipulation of the input processing logic.
The Leak: An attacker can force the model to override its initial instructions (e.g., "Ignore all previous commands...") and reveal its confidential prime prompt or output sensitive information from its active working memory. In RAG systems, a malicious string embedded in a document can trick the model into revealing internal file paths or API endpoints it was instructed to use but never display.
The Reliable System Imperative: This requires a dedicated Red Teaming effort. We must adopt an adversarial mindset, constantly testing the model’s instruction following resilience and its ability to distinguish between benign user input and malicious system command overrides.
Not all compromises occur at the model's output layer; the infrastructure surrounding the LLM often creates a downstream risk.
The Problem: To ensure model quality and enable future fine-tuning, every prompt, completion, and intermediate piece of data (especially RAG document chunks) is logged. If these logs land in a standard, unencrypted database, an unsecured cloud storage bucket, or an improperly configured third-party analytics tool, the data is compromised.
The Leak: Even if the final output to the user is perfectly sanitized, the system may have temporarily retrieved a highly sensitive document chunk internally. That sensitive data now resides in a log file, potentially moving outside the security boundary of the primary application.
The Reliable System Imperative: Comprehensive data flow auditing and governance is essential. We must classify and sanitize all intermediate data immediately, masking or deleting sensitive segments before they are written to any long-term storage or shipped to external evaluation systems.
Securing LLMs requires blending the security insights of networking, the systematic approach of software engineering, and the deep understanding of ML architecture.