LLMs in the Testing Trenches
Self-Healing Tests and Mutation Testing at Scale

Search for a command to run...
Self-Healing Tests and Mutation Testing at Scale
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

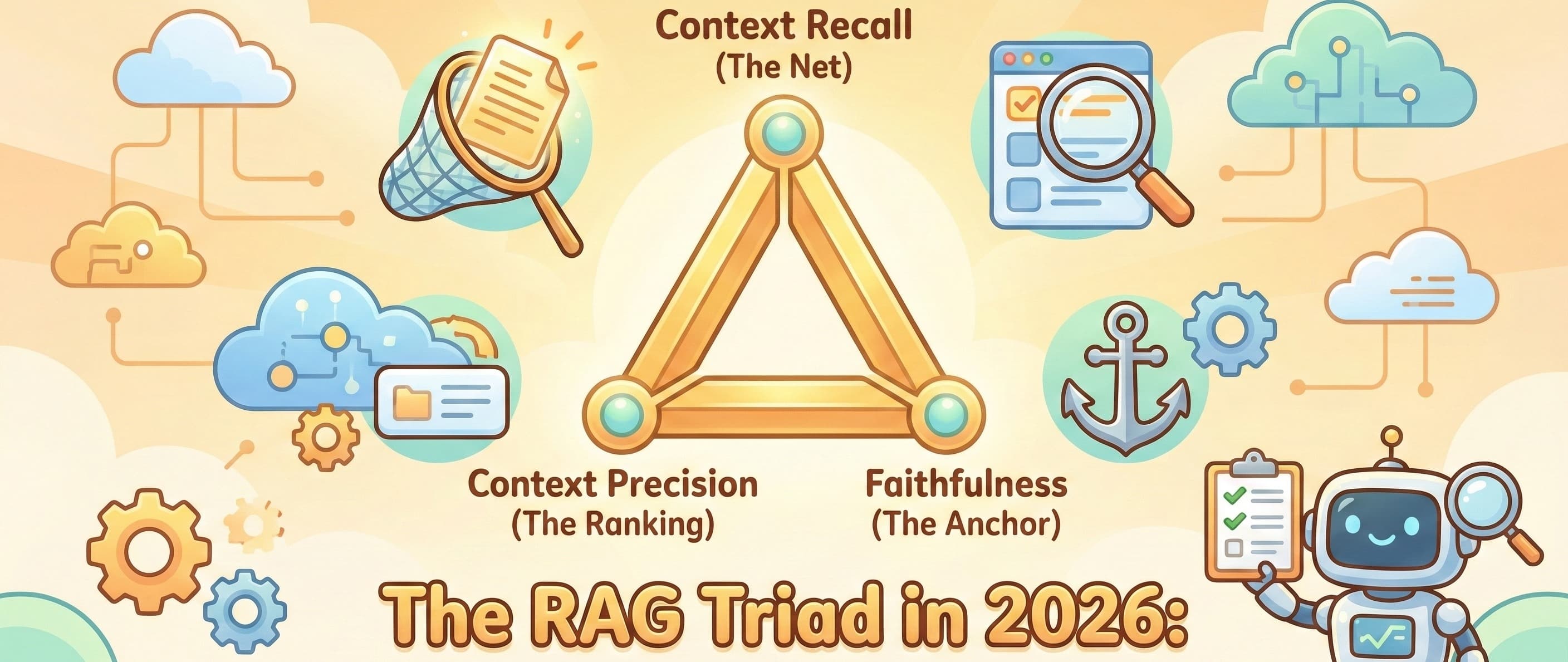
It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

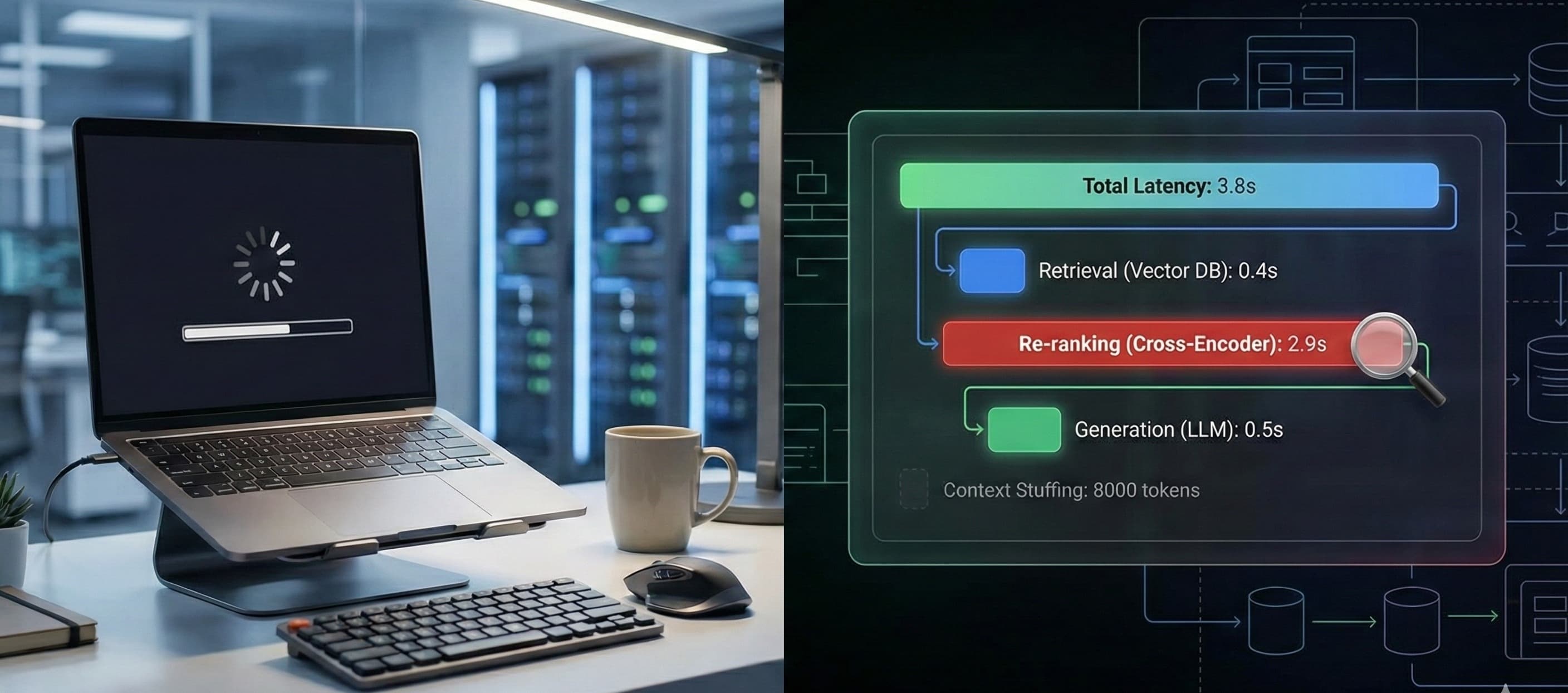
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
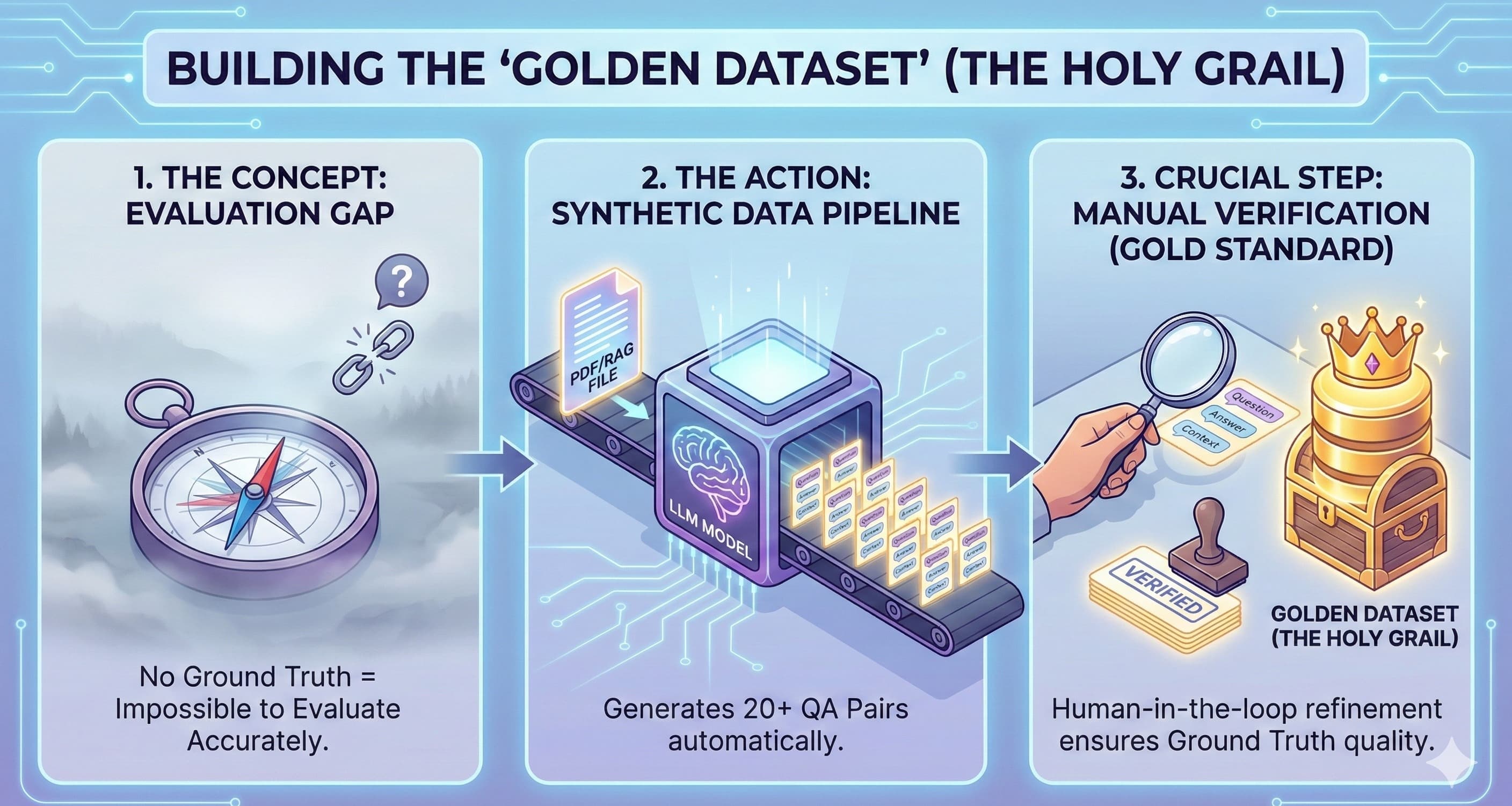
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
It’s 3 AM, and the CI/CD pipeline is a sea of red. The main deployment is blocked, and panic is setting in. And the cause? A real, show-stopping bug?
No. A developer pushed a minor UI tweak, changing a button's id from #submit-order to #checkout-submit.
Half the regression suite just became worthless. This is the daily grind for QA engineers: the constant, tedious maintenance of brittle tests. It’s a drain on time, morale, and budget.
For the last few years, our relationship with Large Language Models (LLMs) has been one-sided. We’ve been the testers, poking and prodding them as the System Under Test (SUT), checking for bias, accuracy, and security flaws.
But the roles are reversing. The LLM is no longer just the patient; it’s becoming the doctor. It's evolving into a powerful co-pilot in the QA process itself.
In this post, we'll explore two cutting-edge applications that shift the LLM from the system-under-test to a powerful testing tool: self-healing tests that fix themselves and intelligent mutation testing that helps us build truly robust applications.

The single greatest time-sink in test automation is maintenance. Brittle selectors (XPath, CSS Selectors, etc.) are the primary culprits. They break with the slightest front-end refactor, leading to false negatives that erode trust in the test suite.
Self-healing tests offer a radical solution: What if the test could fix itself?
The LLM-Powered Solution
Instead of just failing, a test can be wrapped in a smart error handler. When a locator fails, this new workflow kicks in:
Test Fails: A test runner (like Playwright or Selenium) attempts to click page.click("#old-submit-button") and throws a "selector not found" error.
Handler Activates: Instead of immediately failing the test, a custom error handler catches this specific exception.
Context is Gathered: The handler packages up the crucial context: the broken selector (#old-submit-button), the error message, and, most importantly, the current state of the page's DOM.
The Prompt is Sent: This context is fed to an LLM with a highly specific, role-based prompt.
Example Prompt: "You are an expert QA automation engineer. The selector '
#old-submit-button' failed to find an element. Based on the provided DOM, analyze the page structure and generate a new, more robustdata-testidor CSS selector for the element that semantically represents the 'Submit' button."
AI Analyzes and Suggests: The LLM doesn't just guess. It parses the DOM, understands the intent (finding a submit button), and suggests a more resilient selector, like button[data-testid='form-submit'].
Retry and Log: The test runner retries the step with the new selector. If it passes, the test continues, and the successful "heal" is logged for a human to review later.
Here’s what this looks like conceptually in code:
Python
try:
page.click("#old-submit-button")
except SelectorError as e:
print("Selector failed. Attempting self-heal...")
current_dom = page.content()
# Call to an LLM API
new_selector = llm_fix_selector(
old_selector="#old-submit-button",
error_message=str(e),
dom=current_dom
)
if new_selector:
print(f"Heal successful. Retrying with: {new_selector}")
page.click(new_selector) # Retry the action
log_successful_heal(test_name, "#old-submit-button", new_selector)
else:
raise e # Fail the test if no fix is found
This transforms test maintenance from a reactive chore into a proactive, automated process, freeing up engineers to find real bugs.
How do you know your tests are actually good? Code coverage is notoriously misleading. 100% coverage might just mean your tests executed the code, not that they validated anything.
Mutation Testing is the gold standard for test quality. The process is simple:
Introduce a small bug (a "mutant") into your code (e.g., change a + to a -).
Run your tests.
If your tests fail, the mutant is "killed." If they pass, your tests are blind to that kind of bug.
Historically, this technique has been painfully slow and the mutants themselves simplistic. An LLM, however, can act as a semantic mutant generator, creating sophisticated bugs that mimic real human error.
Consider the difference:
Simple Mutant: Changes if (cart_total > 100) to if (cart_total >= 100). Any decent boundary-condition test will kill this mutant.
LLM-Generated Mutant: You give the LLM a function and a prompt:
"You are a senior developer. Review this Python function for calculating shipping costs. Introduce a subtle, plausible logical flaw. For example, incorrectly handle the edge case for shipping to non-contiguous states like Hawaii or Alaska, or forget to apply a discount after tax is calculated."
The LLM can create a mutant that only fails for a very specific, complex scenario. This is a bug a junior developer might actually introduce.
Why it's a Game-Changer: This makes mutation testing practical. In seconds, you can generate a dozen high-quality, diverse, and semantically relevant mutants. By testing against these "smarter monsters," you force your test suite to become truly robust, guarding against complex logical errors, not just simple syntax changes.
This all sounds great, but an LLM is not a magic wand. It's a powerful tool that, if used blindly, can cause its own problems.
Prompt Engineering is Everything: The quality of the self-heal or the mutant is 100% dependent on the quality of your prompt and the context you provide. Garbage in, garbage out.
Don't Automate the Automation (Blindly): This is an augmentation strategy, not a full replacement. The human engineer must remain in the loop.
Logging is Non-Negotiable: Every self-heal attempt, successful or not, must be logged for review. You need an audit trail.
Human Review is Essential: A human must review and approve any permanent changes to the test suite. An LLM might "fix" a test to make it pass, but in doing so, it could fundamentally misunderstand the test's intent and stop testing the correct functionality.
You don't need a massive new platform to start. You can begin experimenting by using libraries like LangChain or LiteLLM to act as a bridge between your test runner (like pytest or jest) and a model API (like GPT-5, Gemini, or Claude).
We've explored two powerful ways to use LLMs as testing partners: reducing maintenance with self-healing tests and increasing quality with intelligent mutation testing.
This is more than just a new tool; it's an evolution of the QA role itself. We are moving from being manual scriptwriters to being conductors of intelligent testing systems. The future of quality assurance isn't just about writing test code; it's about leveraging AI to build more resilient, insightful, and adaptive quality processes.
You don't need to rebuild your entire framework tomorrow. Start small.
Pick one flaky test in your suite that always breaks. Next time it fails, before you fix it, copy the DOM and the error. Paste them into an LLM and ask it to suggest a better selector.
See what happens. The journey into this new trench starts with a single prompt