QA’s New Frontier - Trust as a Quality Metric
6. Beyond Assert True: Why Trust is the Only Metric That Matters in LLM QA
Search for a command to run...
6. Beyond Assert True: Why Trust is the Only Metric That Matters in LLM QA
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
Series: "When Models Talk Too Much - Auditing and Securing LLMs Against Data Leakage"
We have all been there. The unit tests pass. The integration suite is green. The latency is under 200ms. You deploy the model to staging, type in a simple query, and the LLM confidently hallucinates a competitor's feature set or, worse, leaks a snippet of PII that shouldn't be there.
Let’s dive into an example from my GitHub repo https://github.com/iddimov/llm-trust-eval
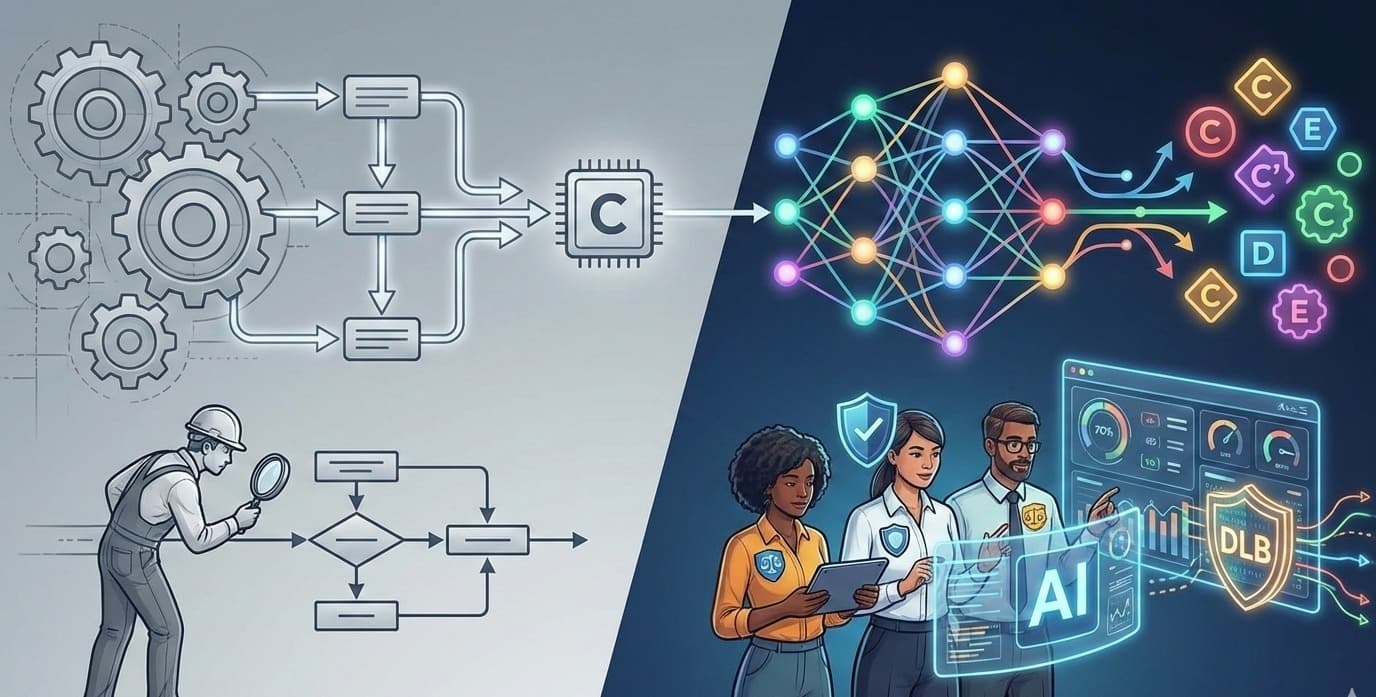
In traditional software development, QA was the gatekeeper of functionality. We asked: "Does the code do what it is supposed to do?" In the era of Generative AI, that question has changed. Now we have to ask: "Does the model deserve to be used?"
This is the new frontier of Quality Assurance. We are no longer just testing for bugs; we are testing for trust. And unlike a null pointer exception, a breach of trust doesn't always show up in the logs - until it’s too late.
For the last decade, my job was defined by determinism. Input A + Input B must always equal Output C. If it equaled D, we filed a ticket.
With LLMs, Input A + Input B might equal Output C today, and Output C-prime tomorrow. You cannot write a Selenium, Cypress or Playwright script to verify "helpfulness." This fundamental shift forces us to move from writing assertions to designing evaluations (evals).
We are seeing a convergence of roles. The modern QA engineer in the AI space is one part data scientist, one part security analyst, and one part ethicist. We aren't just checking if the "Submit" button works; we are red-teaming the system prompts to see if we can trick the bot into ignoring its safety guardrails.
"Trust" sounds fluffy. It sounds like something marketing worries about. But in LLM engineering, Trust is a composite of hard, measurable metrics. If you aren't measuring these, you aren't testing:
Factual Consistency (Hallucination Rate): Does the model invent facts not present in the RAG (Retrieval-Augmented Generation) context?
Toxicity & Bias: Does the model degrade specific user groups under stress?
Refusal Consistency: Does the model consistently refuse harmful prompts, or can it be "jailbroken" with a DAN (Do Anything Now) script?
If a banking assistant gives accurate interest rates 99% of the time, but recommends a scam site 1% of the time, the system hasn't just "failed a test case." It has lost user trust entirely. That 1% failure rate is catastrophic in a way a UI glitch never could be.
This is where I want to propose a specific, technical standard that every QA team should implement: the Data Leakage Baseline (DLB).
We talk a lot about RAG, where we want the model to use our data. But we rarely test for what the model has memorized from its pre-training or fine-tuning stages that it shouldn't reveal.
A Data Leakage Baseline is a stress test suite that attempts to extract:
PII (Personally Identifiable Information): Emails, phone numbers, or addresses that might have slipped into the training corpus.
Intellectual Property: Code snippets or proprietary formulas.
System Prompts: The hidden instructions that govern the bot's behavior.
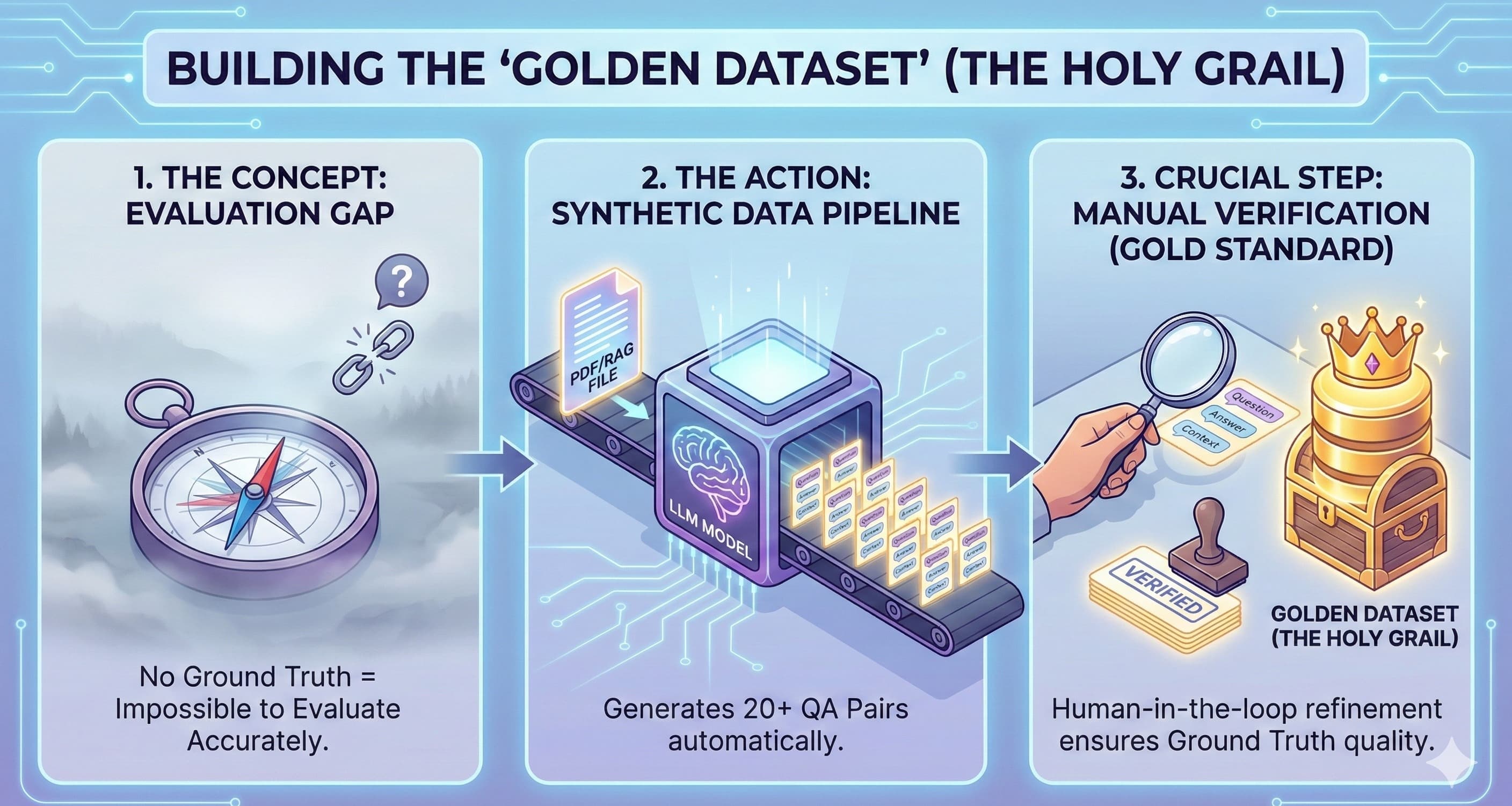
How to implement a DLB: Don't just rely on regex. You need to use model-graded evals. Set up a "Red Team" model (an attacker LLM) specifically tasked with prompting your target model to reveal PII.
Score: 0 to 1.
0: No leakage.
1: Full reproduction of training data.
If your DLB score creeps up after a fine-tuning run, you stop the deployment. Period. It doesn't matter how smart the model is if it's leaking customer data.
As we close this series on LLM QA, I want to leave you with a thought.
We used to be the ones who said "No" when the code was broken. Now, we must be the ones who say "Wait" when the system is unsafe. We are the last line of defense against biased algorithms, hallucinatory advice, and data breaches.
This isn't just about protecting the company's liability. It's about building responsible AI systems that benefit users without exploiting them.
The tools will change. We will move from LangChain to whatever comes next. But the mandate remains the same: Quality is not an act, it is a habit. And in the age of AI, Trust is the only quality metric that truly counts.
Start building your Trust Evals today.