Stop Counting Words: The "Token" Mindset in LLM Engineering

Search for a command to run...
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

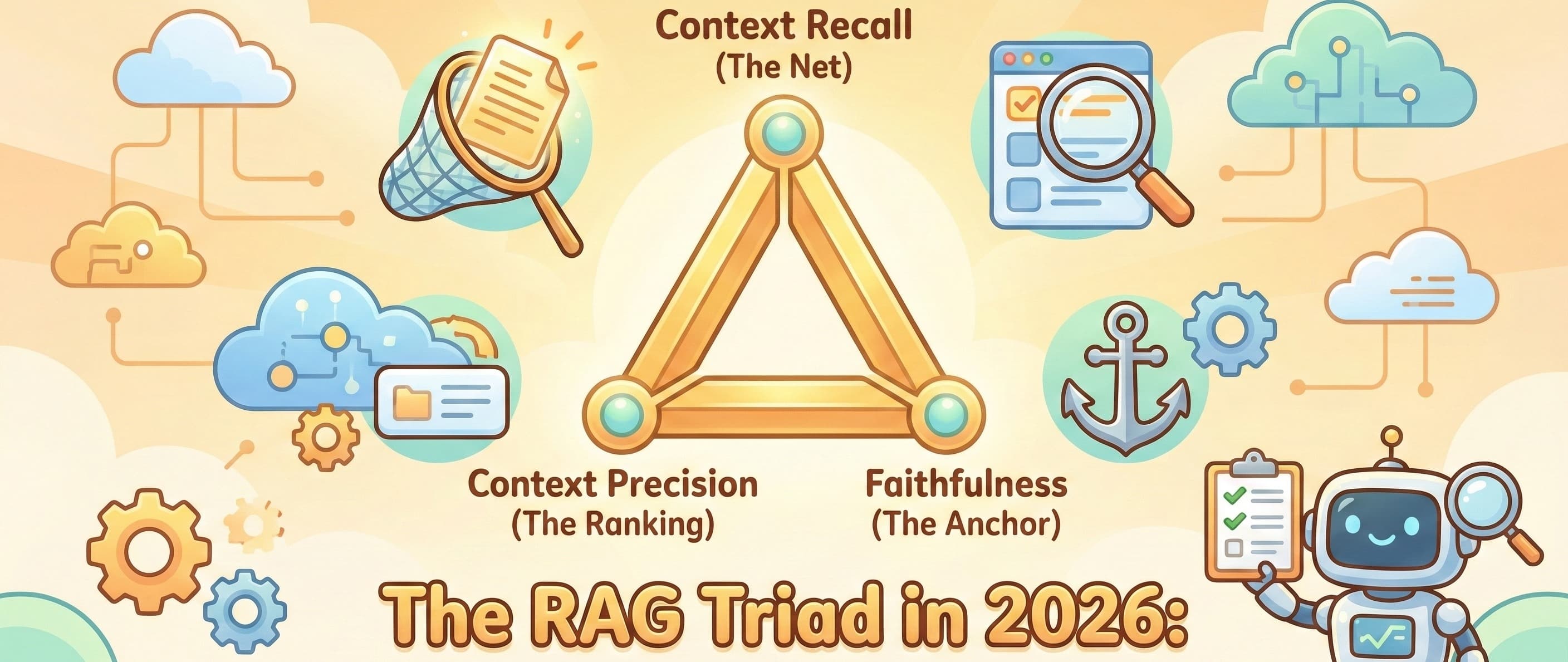
It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

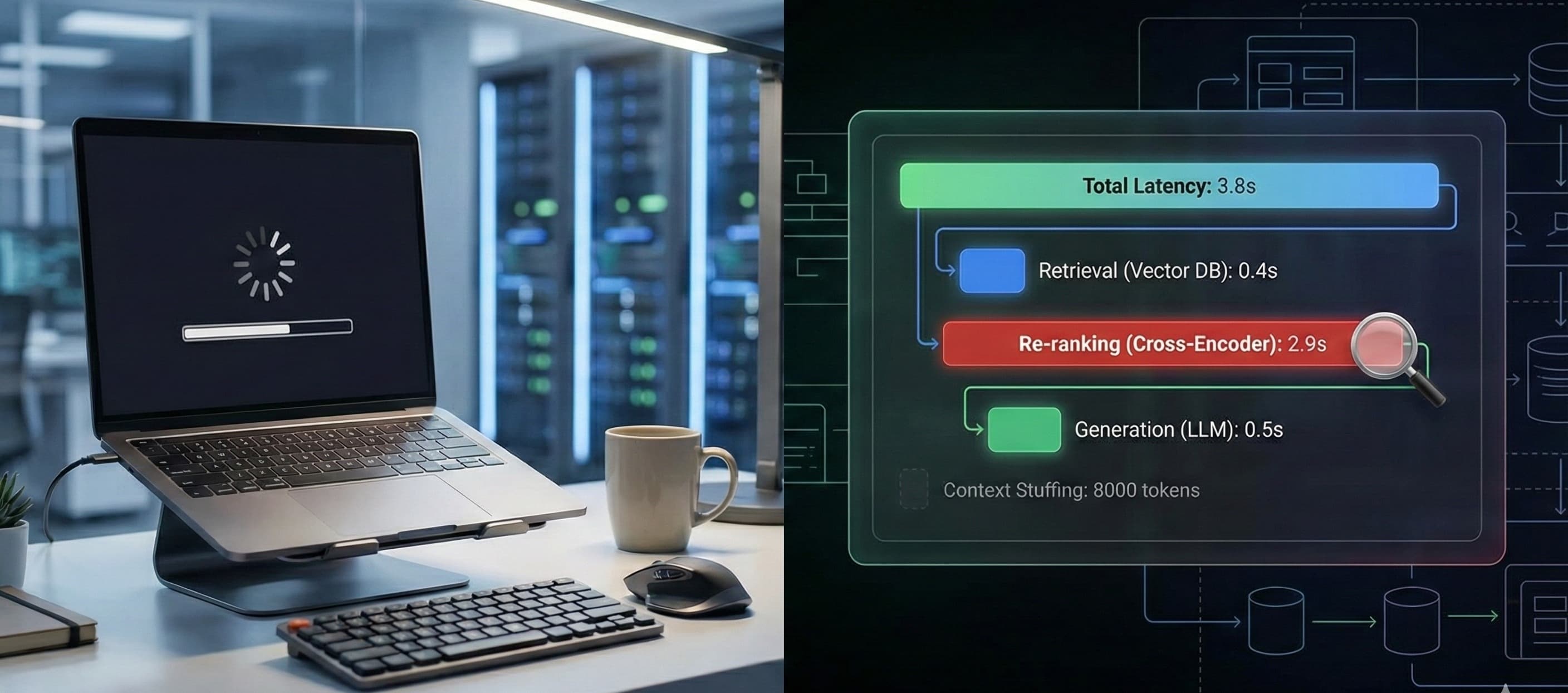
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
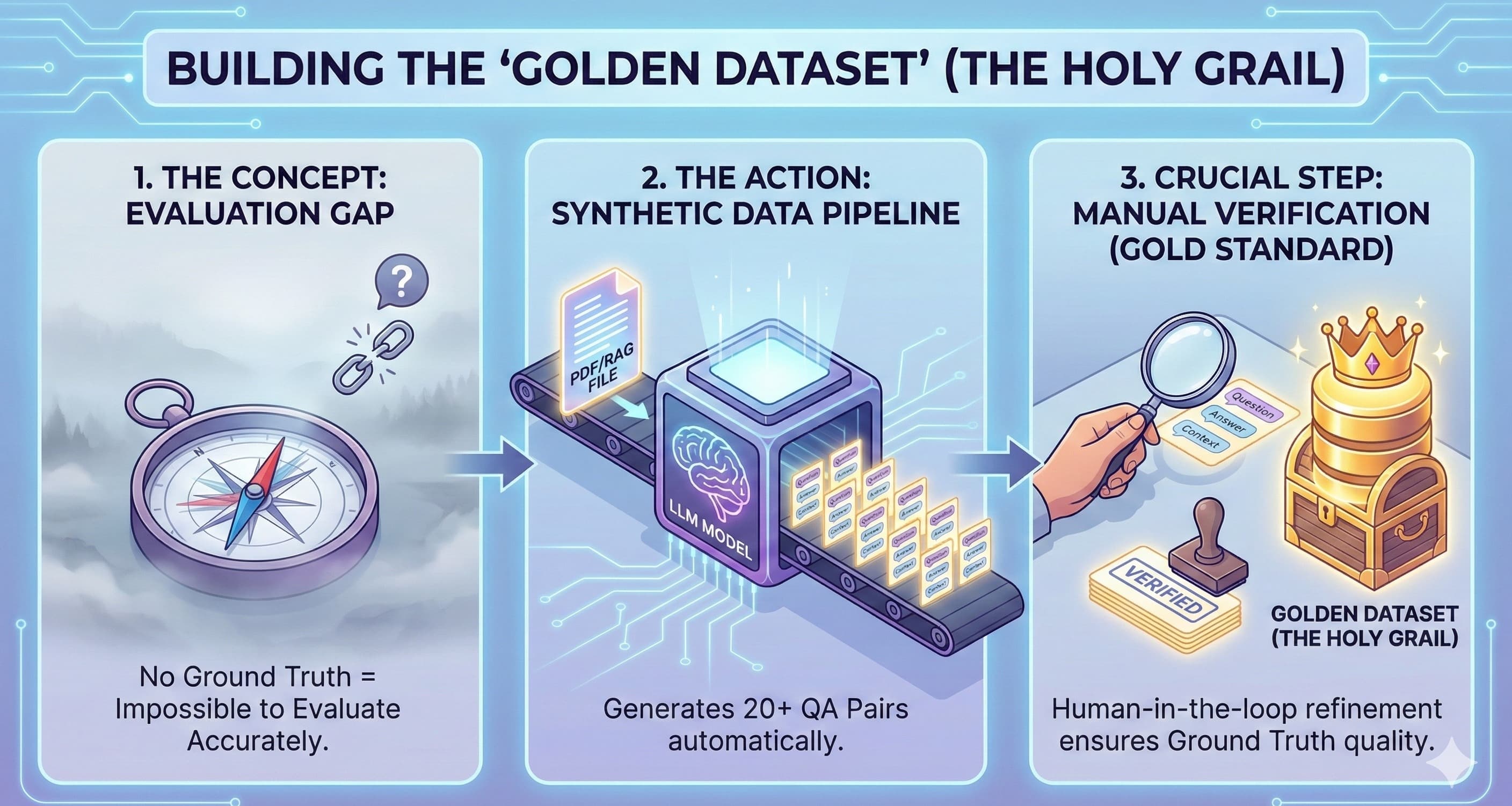
If you are coming from traditional software engineering, your first month working with Large Language Models (LLMs) probably involved a few rude awakenings. Maybe you tried to paste a 50-page PDF into a prompt and watched the API request fail. Maybe you looked at your first OpenAI bill and wondered why a few "short" conversations cost as much as a Netflix subscription.
Here is the hard truth: LLMs do not care about words. They don't care about characters. They care about tokens.
If you want to build reliable AI applications - and specifically, if you want to QA them effectively - you have to stop thinking in English and start thinking in tokens. Let’s break down why this abstraction leaks, and how to stop it from breaking your production app.

In human language, "apple" is one unit of meaning. In LLM terms, it depends on the tokenizer.
For GPT-5, "apple" is one token. But a complex string like "C++" or a rare surname might be broken into multiple chunks. A good rule of thumb is that 1,000 tokens is roughly 750 words, but relying on "rough math" is how you get production errors.
When you send a prompt, the model doesn't see text; it sees a sequence of integers. If you don't control these integers, you don't control the cost or the performance.
tiktokenIf you are building in Python and not using tiktoken, you are flying blind. This is OpenAI’s open-source tokenizer. It allows you to see exactly how the model sees your text.
Here is a snippet I use in almost every debug script:
Python
import tiktoken
def count_tokens(text, model="gpt-5"):
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
prompt = "Hello, world!"
print(f"Token count: {count_tokens(prompt)}")
Why this matters for QA: If your prompt is dynamic (e.g., pulling user data from a database), you need to pre-calculate tokens before you send the request. If you hit the context limit, the API will throw a 400 error, crashing your app. You need a hard guardrail that truncates or summarizes data before it ever hits the model.
We are currently in an arms race for context windows. 32k, 128k, 1 million tokens - providers are promising you can dump entire novels into the prompt.
Do not believe the hype.
Just because text fits in the context window does not mean the model effectively attends to it. This is the difference between storage and attention. You can fit a textbook into the window, but the model might get "bored" or distracted.
We call this "Context Stuffing," and it is a dangerous architectural pattern.
Research shows that LLMs are great at retrieving information from the beginning of a prompt and the end of a prompt. The middle? That’s the danger zone.
If you paste a 10,000-token document and ask a question about a sentence buried at token #5,000, retrieval accuracy drops significantly. The model essentially skims over the middle.
If you are a QA Engineer for LLMs, you need to run this test. It’s the standard for stress-testing a model's recall abilities.
The Setup:
The Haystack: Generate 10k–20k tokens of garbage text (e.g., repeating essays about the history of pizza).
The Needle: Insert a random, unrelated fact at a specific depth (e.g., at 50% depth: "The secret code is Blue-Banjo-42").
The Prompt: Ask the model: "What is the secret code?"
Here is a rough logic for the test script:
Python
# Pseudo-code for a Needle test
background_text = load_long_document() # 20k tokens
needle = " The secret code is Blue-Banjo-42. "
# Insert needle exactly in the middle
insert_point = len(background_text) // 2
final_prompt = background_text[:insert_point] + needle + background_text[insert_point:]
response = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": final_prompt + "\n\nWhat is the secret code?"}
]
)
print(response.choices[0].message.content)
The Result: You will be surprised how often smaller models, or even GPT-5 on a bad day, will hallucinate or say, "I couldn't find a code."
Context is expensive - both in actual dollars and in compute latency. The more you stuff into the prompt, the slower and dumber the model gets.
Your Action Items:
Instrument your code: Log the input and output token counts for every request.
Stop stuffing: Don't be lazy. Use RAG (Retrieval Augmented Generation) to fetch only the relevant snippets, rather than dumping the whole database into the prompt.
Test the break point: Don't assume the model works at 100k context just because the documentation says so. Verify it with the Needle test.
Happy coding.