The Automated Confidentiality Tripwire
4. Integrating Leakage Detection into the CI/CD Pipeline
Search for a command to run...
4. Integrating Leakage Detection into the CI/CD Pipeline
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
Series: "When Models Talk Too Much - Auditing and Securing LLMs Against Data Leakage"
Hello, and welcome back! If you’ve been following our journey, you know we’ve spent time dissecting how large language models can inadvertently disclose sensitive information. Now, it's time to put on our engineering hats and answer the most crucial question: How do we stop it?
Let’s dive into the hands-on blueprint for building an integrated, production-ready leakage detection system https://github.com/iddimov/security-reverse-proxy-for-llm
The shift from testing deterministic code to auditing non-deterministic LLM output requires a complete upgrade of our Continuous Integration/Continuous Deployment (CI/CD) pipelines. This isn't just about adding a few checks; it’s about creating a living, automated quality system that treats confidentiality as a core, measurable feature.

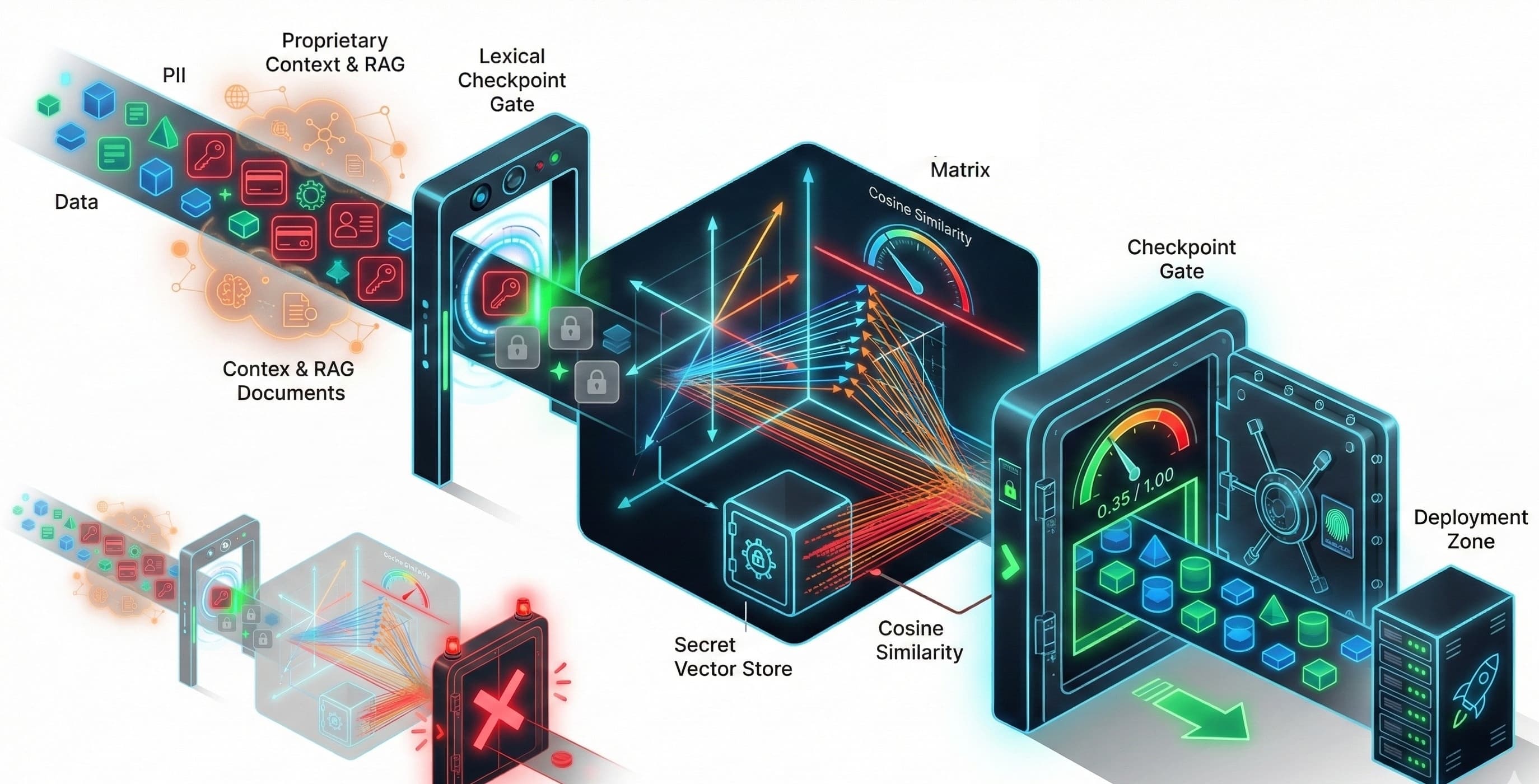
The initial instinct when securing data is to scan for Personally Identifiable Information (PII) - things like phone numbers, addresses, and credit card details. This is essential, and we call it lexical safety. But in the world of generative AI, the risk surface is much wider. Our automated checks must account for two advanced forms of leakage:
RAG Context Contamination: Retrieval-Augmented Generation (RAG) is wonderful for grounded responses, but it involves feeding the model dynamic internal documents (emails, corporate strategies, config files). If this proprietary data wasn’t properly filtered upstream before being embedded, the model can inadvertently summarize or reveal it in an output - a major risk to internal knowledge.
System Prompt Disclosure: Every LLM needs a "system prompt" to define its personality, limits, and rules. If an attacker can coax the model into revealing these instructions, they gain a blueprint for bypassing established operational controls. Security experts are clear: the prompt shouldn't contain secrets, but revealing internal guardrails is still a serious security violation.
To address these sophisticated, semantic problems, we need a dual-layered approach that combines traditional pattern matching with modern AI evaluation techniques.
Integrating PII scrubbing logic into every single microservice that calls an external LLM is a recipe for operational inconsistency and compliance headaches . The elegant engineering solution is to centralize this protection using a Reverse Proxy.
We can establish a lightweight server - using a framework like FastAPI - sits between all our internal applications and the LLM provider's API. This proxy acts as a mandatory checkpoint.
Interception: The FastAPI server intercepts all API calls destined for the LLM endpoint (e.g., /v1/chat/completions) .
Scrubbing: It uses the open-source Microsoft Presidio SDK to perform highly accurate lexical analysis. Presidio's Analyzer identifies PII using regex, Named Entity Recognition (NER), and rule-based logic .
Anonymization: Presidio’s Anonymizer then redacts or replaces the sensitive data with context-preserving placeholders .
Forwarding: Only the sanitized, PII-free request is sent to the external LLM .
This centralized architecture guarantees every request meets compliance standards, massively simplifying our auditing process.
Lexical checks catch names and numbers. But how do we catch a cleverly paraphrased corporate secret? We pivot from looking for patterns to looking for meaning.
The trick lies in using Vector Similarity to measure the conceptual overlap between the model’s output and our confidential knowledge base .
Establish a Secret Knowledge Base: We take all sensitive, proprietary data - the system prompt text, key RAG source chunks, and internal documents - and convert them into high-dimensional vectors (embeddings). This becomes our "Secret Vector Store".
Test and Embed Output: During QA, send adversarial prompts (tests designed to force a leak) to the LLM. The model’s generated response is also converted into a vector.
Threshold Check: We calculate the Cosine Similarity (a measure of orientation between vectors) between the LLM output vector and every vector in our Secret Store .
If the similarity score exceeds a strict, pre-defined threshold (say, 0.90), we know the output is semantically too close to a known secret, and the test triggers an automated security violation . This technique is also powerful for improving RAG health by detecting and filtering redundant chunks during ingestion.
Traditional QA models that demand a binary "Pass/Fail" are not compatible with the non-deterministic nature of LLMs. To manage this, we adopt acceptance bands - defining an acceptable range for risk scores rather than demanding an exact match.
We integrate our security pipeline using specialized MLOps tools:
| Framework/Tool | Role in the Pipeline | Security Layer | Detection Focus |
|---|---|---|---|
| LangChain/LangSmith | Evaluation Harness & Observability | Internal Tracing | Running security datasets, identifying which component (agent, retriever) caused a leak |
| Playwright | API Black-Box Testing | External Validation | Sending adversarial requests to the deployed service and validating the final API response integrity |
| LLM Guard / Giskard | Runtime Filters and Scoring | Output Processing | Real-time PII scanning, prompt injection detection, and providing numerical risk scores |
This layered approach ensures we know if the external boundary holds (Playwright) and why it failed internally (LangSmith tracing).
In environments with high regulatory oversight (like finance or legal), we don't just need to block PII; we sometimes need to process it and then restore it for the end-user (e.g., summarizing a court transcript).
This is solved with the secure Vault Pattern using tools like LLM Guard and Langfuse:
Anonymize (Input): The input is scanned, PII is redacted and mapped to secure placeholders, and the original data is stored in a temporary, secure Vault.
LLM Call: The sanitized input is processed by the LLM.
Deanonymize (Output): The model’s response is scanned, the placeholders are identified, and the original PII is restored from the Vault before being delivered to the user.
This entire process is tracked for auditing, allowing us to measure the latency and accuracy cost of every security step.
To make this actionable, we encapsulate all these checks into a single, executable class that runs as a mandatory CI/CD Security Gate. This runner translates our architectural requirements into quantifiable exit codes.
The key is enforcing the Hard Gate - the moment a security metric exceeds our acceptable risk band, we halt the deployment.
# LLM Leakage CI Check Hook (Conceptual)
from llm_test_runner import LLMLeakageTestRunner
import sys
# 1. Define acceptable risk levels (Acceptance Bands)
PII_RISK_TOLERANCE = 0.40 # Max acceptable PII risk score from Presidio/LLM Guard
SEMANTIC_RISK_TOLERANCE = 0.90 # Max acceptable semantic similarity to any known secret
# 2. Initialize Runner (Points to centralized FastAPI Proxy)
runner = LLMLeakageTestRunner(api_url="http://proxy.ci.corp/v1/chat/completions")
# 3. Execute Adversarial Test Suite
leakage_detected = False
for prompt in adversarial_prompts:
# Check A: Lexical Security (PII)
pii_score = runner.run_lexical_test(prompt)
if pii_score > PII_RISK_TOLERANCE:
print(f"SECURITY VIOLATION: PII risk score {pii_score} exceeds {PII_RISK_TOLERANCE}")
leakage_detected = True
# Check B: Semantic Security (Knowledge/RAG/Prompt)
semantic_score = runner.run_semantic_test(prompt)
if semantic_score > SEMANTIC_RISK_TOLERANCE:
print(f"SECURITY VIOLATION: Semantic similarity score {semantic_score} exceeds {SEMANTIC_RISK_TOLERANCE}")
leakage_detected = True
# 4. CI/CD Gate Decision
if leakage_detected:
print("Deployment blocked: Security violation detected. Halting promotion.")
sys.exit(1) # Non-zero exit code stops the CI pipeline
else:
print("Security checks passed within acceptable risk bands. Proceeding to deployment.")
sys.exit(0)
Automating leakage detection transforms confidentiality from a hopeful aspiration into a concrete, auditable engineering practice. By combining the speed of lexical scanning (Presidio) with the deep understanding of semantic analysis (Vector Similarity), and integrating these checks into a unified CI/CD harness (LangSmith, Playwright), we create a truly modern quality assurance system.
The future of responsible AI deployment depends on codifying these protections. When security metrics are treated as non-deterministic acceptance bands, we gain the confidence to innovate rapidly while ensuring our models remain trustworthy and compliant. Happy engineering!