The Evaluator's Toolkit
LLM-as-a-Judge, Automated Evals, and Continuous Monitoring
Search for a command to run...
LLM-as-a-Judge, Automated Evals, and Continuous Monitoring
No comments yet. Be the first to comment.
It’s 2026. If you are still manually updating CSS selectors because a div moved three pixels to the left, you are doing it wrong. For the last decade, we’ve been stuck in a loop of "write, break, fix,

It is 2026. GPT-5, DeepSeek V3.2, Gemini 3 pro… are here, and reasoning capabilities are nothing short of extraordinary. But let’s be honest: if your RAG (Retrieval-Augmented Generation) pipeline feed
The "Notebook Phase" is the most dangerous place in AI engineering. We’ve all been there. You hack together a prompt, chain a few API calls in a Jupyter notebook, and hit Shift+Enter. The output is magic. You show your PM, they’re thrilled, and you s...

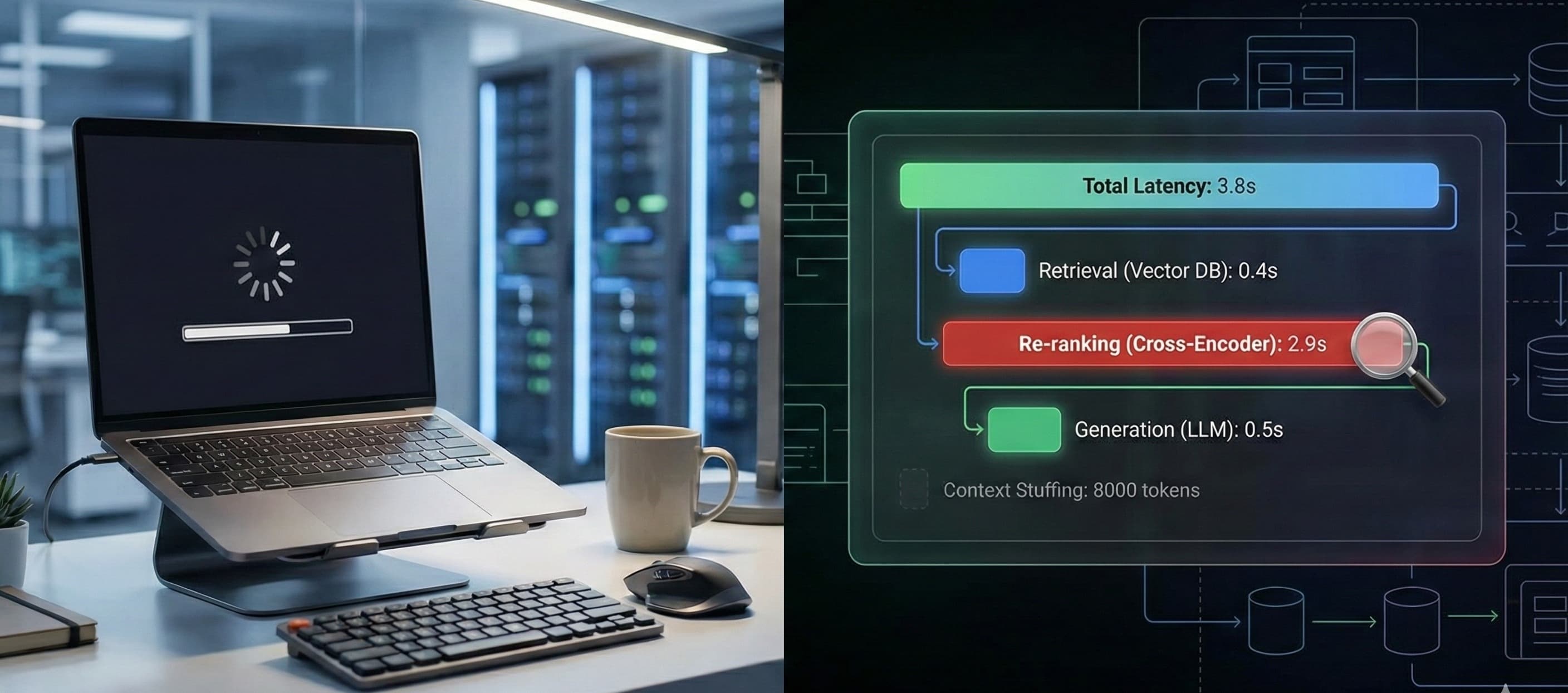
You hit "Enter." The loading spinner starts spinning. You wait. You take a sip of coffee. You wait some more. Finally, five seconds later, the LLM spits out an answer. It’s accurate, sure. But in the world of software, five seconds is an eternity. W...
If I see one more "vibe check" evaluation in a pull request, I’m going to scream. You know the drill. You tweak the prompt, you run a few queries in the playground, it "feels" better, and you merge. Two days later, a user asks a question about a spec...
You’ve done it. Your new RAG-based chatbot is slick, the demos are blowing people away, and the early feedback is glowing. You’re feeling pretty good.
Then the meeting happens.
The engineering lead wants to swap out the embedding model for a newer, cheaper one. The product manager has an idea to tweak the system prompt to make the bot more “personable”. Your job, as the guardian of quality, is to answer a simple question: will these changes make our app better, or will they silently introduce a dozen new ways for it to fail?
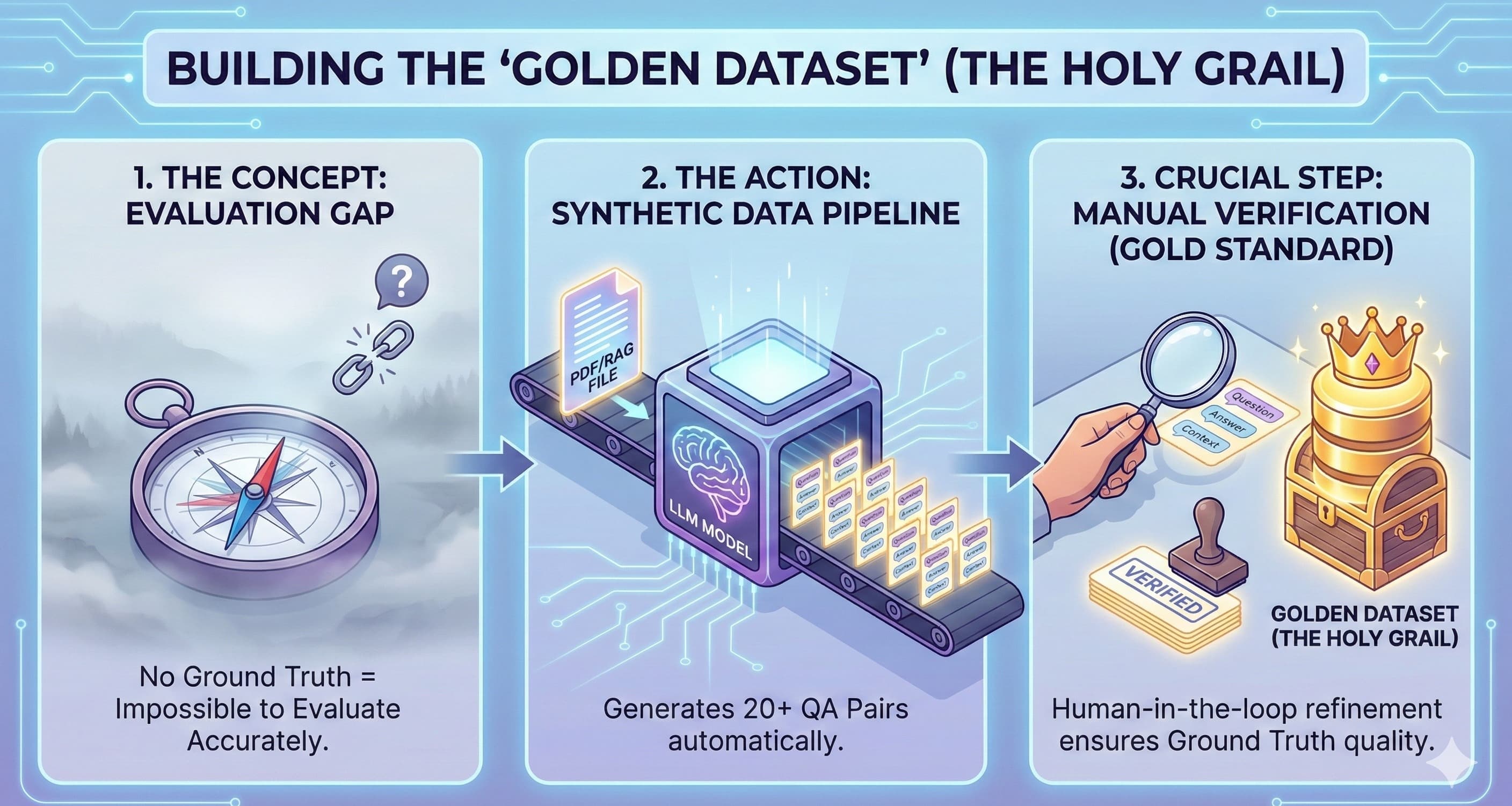
If your gut reaction is to open a spreadsheet, manually type in 100 questions, and subjectively grade the outputs for the next three days… you already know that’s a losing battle. That approach doesn't scale, it's painfully slow, and every evaluator will have a slightly different opinion.
To build serious, production-grade AI, we need to get serious about how we evaluate it. It’s time to upgrade from spreadsheets to a proper system. Welcome to the Evaluator's Toolkit—a three-layer strategy to make your LLM testing scalable, repeatable, and deeply integrated into your workflow.

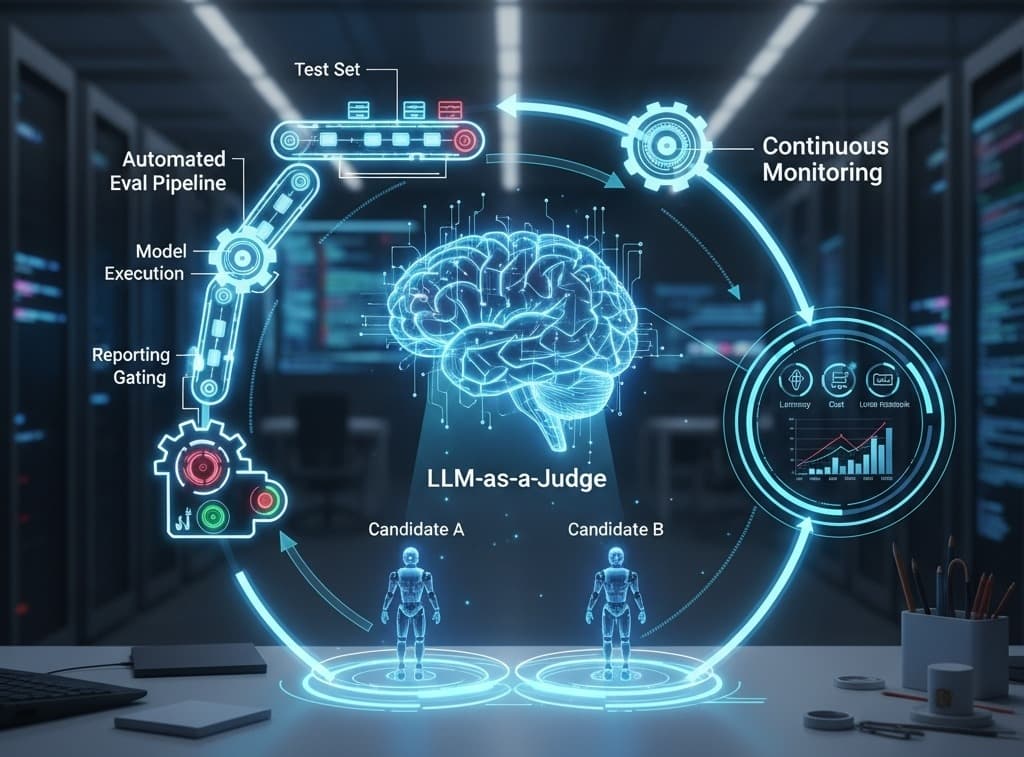
The first tool in our kit is probably the most talked-about right now: LLM-as-a-Judge.
The idea is both simple and incredibly powerful. We use a highly advanced model (think GPT-5, Claude Sonnet 4.5) as an impartial expert to evaluate the output from our application’s model. Instead of a human trying to juggle criteria like “relevance,” “clarity,” and “faithfulness,” we delegate the task to the judge.
In my experience, this works best in two main flavors:
Pairwise Comparison: You give the Judge a single prompt and two different answers (say, from your old model vs. your new one) and ask a simple question: "Which response is better, A or B?" Humans are much better at relative comparisons, and it turns out LLMs are too. This is great for A/B testing prompts or models.
Single-Answer Grading (My Preference): This is where the real power is. You give the Judge a single response and a detailed scoring rubric. The quality of your rubric is everything. A lazy prompt gets you lazy results. A sharp, well-defined prompt gets you structured, reliable data.
Here's a snippet of a rubric-based judge prompt I've used for a customer service RAG bot. The key is to be incredibly specific about what you value.
You are an expert QA evaluator. Your task is to assess the quality of a response from a customer service chatbot based on a user's query and the provided context from our knowledge base.
[CONTEXT]
{{retrieved_context_from_docs}}
[USER QUERY]
{{user_query}}
[CHATBOT RESPONSE]
{{chatbot_response}}
Please evaluate the response based on the following criteria on a scale of 1-5 (1=Very Poor, 5=Excellent). Provide a score for each, a brief justification, and then a final "overall_score". Output your response *only* in JSON format.
{
"relevance_score": "Does the response directly answer the user's query? (1=Off-topic, 5=Perfectly addresses the query)",
"faithfulness_score": "Is the response fully grounded in the provided context? (1=Contains made-up information, 5=Completely supported by the context)",
"clarity_score": "Is the response easy to understand and free of jargon? (1=Confusing and verbose, 5=Clear and concise)"
}
But it's not a silver bullet. There are a couple of gotchas to keep in mind. Judge models can have biases (like favoring longer answers or the first answer they see), and calling a top-tier model thousands of times isn't free. Use it wisely on a well-curated “golden dataset” of your most important and challenging test cases.
Manually running a judge script is a neat trick, but the real magic happens when you make it boring. By “boring”, I mean fully automated and integrated into your CI/CD pipeline, just like your unit tests.
The goal is to have an evaluation pipeline that runs on every single commit that could affect model quality. Think of it as a set of automated pre-flight checks.
Here’s how it works:
Trigger: A developer pushes a change - a new prompt template, a tweak to the RAG retrieval algorithm, or a new fine-tuned model.
Execute: The pipeline automatically spins up, runs the new version of your app against your golden dataset, and saves all the outputs.
Evaluate: This is the multi-pronged testing stage. It runs a few things in parallel:
It sends the outputs to your LLM-as-a-Judge for that deep, rubric-based quality check.
It calculates cheaper, faster metrics like BERTScore to check for semantic drift against known-good answers.
It runs deterministic checks for things like PII leakage, toxicity, or whether the output is in valid JSON if that's what the downstream service expects.
Report & Gate: All these scores are logged in a platform like Weights & Biases or MLflow. You can see at a glance how the new version stacks up against the current production version. More importantly, you can set a gate. If the average faithfulness_score drops below 4.2, or if more than 1% of responses are flagged for toxicity, the build automatically fails. The regression never even gets a chance to see the light of day.
This turns evaluation from a multi-day manual chore into a 15-minute, hands-off process.
Okay, so our pre-flight checks are automated. We're clear for takeoff, right?
Not so fast. No evaluation dataset, no matter how good, can truly replicate the chaos of real users. Production is where the real test begins. You need to monitor your app's quality continuously.
This goes way beyond checking for latency and error rates. We need to monitor the behavior of the model itself.
The Obvious Stuff (Operational Metrics): Yes, track your cost per user, your latency, and your API error rates. A sudden spike in any of these is your first warning sign.
The Feedback Loop (User Data): That little thumbs-up/thumbs-down button on your UI? That is pure gold. It's the most direct signal of quality you will ever get. Log every single click and treat it as labeled data.
The Sneaky Stuff (Proxy Metrics): Users tell you things without clicking any buttons. Did the user copy-paste the bot's response? That's a huge signal of success! Did they immediately rephrase their question or abandon the session? That’s a signal of failure. Tracking these engagement metrics can be a powerful proxy for quality.
The Nerdy Stuff (Drift Detection): This is the final frontier. By tracking the vector embeddings of user prompts and model responses over time, you can detect "drift." Are users suddenly asking about a new product feature you haven't added to your knowledge base? Is your model's tone suddenly becoming more verbose? Drift detection systems can alert you to these subtle shifts before they become major problems.
These three tools - Judge, Pipeline, and Monitor - aren't separate stages. They form a powerful, continuous improvement loop.
The production issues and user feedback you catch with Continuous Monitoring are your best source for new, tricky test cases. You feed those right back into the golden dataset that powers your Automated Eval Pipeline. That pipeline, using the LLM-as-a-Judge, ensures that any fix you implement actually works without breaking something else.
The role of an LLM tester is changing. We’re moving from being manual checkers to architects of these complex, automated quality systems. By embracing this toolkit, you can stop guessing and start engineering quality into your AI products from day one.
I'm genuinely curious - what does your evaluation stack look like? What tools or techniques have you found to be indispensable? Drop a comment below