A 3-Layer Framework for Building Bulletproof LLM Applications

It's Monday morning. You check the CI/CD pipeline, and a test that was green all last week is now glowing red. You dive in, expecting to find a rogue commit, but there’s nothing. The code hasn't changed. The test failed because the function that summarizes text, which passed on Friday with the output "The cat sat," has now produced "A cat was sitting."
The logic is sound. The meaning is identical. But your test is broken.
If this scenario feels painfully familiar, you're not alone. You’ve just slammed head-first into the non-deterministic wall of Large Language Models. And it’s a sign that our entire approach to testing needs a fundamental rethink. This isn't about patching old methods; it's about adopting a new philosophy. We must move from verifying exact outputs to evaluating semantic capabilities.
The Core Problem: Deterministic Code vs. Probabilistic Models
For decades, software testing has been built on a bedrock of certainty. We live in a world governed by logic: if you give a function the same input, you expect the same output, every single time. Our tests are a reflection of this world:
assert myFunction(2) == 4
This is predictable, repeatable, and gives us a clear, binary pass/fail.
LLMs operate in a different universe. They are probabilistic systems. Their goal isn't to follow a rigid set of instructions to produce a single correct answer. Their goal is to predict the next most likely word, and the word after that, creating a response that lives within a vast space of valid possibilities. Trying to test a function like summarize(article) with an exact-match assertion is like trying to nail water to a wall. It's the wrong tool for the job.
The Four Horsemen of the LLM Testing Apocalypse
This fundamental difference creates a cascade of new challenges that our old testing playbooks simply weren't designed to handle.
Non-determinism: As our opening story showed, you can run the same prompt through a model twice and get two different, yet equally correct, answers. Traditional assertions that expect a single state are doomed to be flaky and unreliable.
The Infinite Output Space: What is the "correct" way to summarize a news article? There are thousands, maybe millions, of valid combinations of words and sentences. You can't possibly write a test case for every single one.
The Tyranny of Context: A model’s response in a chatbot doesn't just depend on the last user message. It depends on the entire conversation history. Testing a single turn in isolation is like testing a single frame of a movie - you lose the plot completely.
The Composite System Maze: Modern AI applications are rarely a single call to an LLM. They are complex pipelines involving Retrieval-Augmented Generation (RAG), agentic workflows, and tool usage. A failure could be a bad LLM response, but it could also be the RAG system pulling the wrong document, a tool being called with malformed arguments, or the final output parser breaking. The points of failure have multiplied.
The Blueprint for Sanity: The Three-Layer Testing Architecture
So, how do we test something so chaotic? We stop trying to test it as one giant, unpredictable blob. We separate the application into logical layers and apply the right testing strategy to each.
Layer 1: The System Shell (The Deterministic Bedrock)
What it is: This is the predictable scaffolding around your LLM. It includes your API endpoints, data preprocessing and validation, user authentication, and the logic that invokes your tools.
How to Test It: Your old playbook is still perfect here! This layer is deterministic, so use the tools you know and love. Write traditional Unit Tests and Integration Tests with pytest, JUnit, Jest, or your framework of choice. Assert that your API returns a 200 OK, that user input is properly sanitized, and that a function call to your weather tool is made with the correct city name.
Layer 2: The Prompt Orchestration (The Strategic Brain)
What it is: This is the logic that constructs prompts, manages conversational memory, decides which documents to inject for RAG, and parses the structured output from the LLM.
How to Test It: This is a hybrid zone, requiring a mix of old and new techniques.
Logic Validation: Use unit tests to confirm your prompt templates are being populated correctly. You can't test the final LLM output, but you can assert "user_question" in final_prompt.
Semantic Validation: When parsing LLM output (e.g., extracting JSON), don't just test that the output is valid JSON. Perform simple checks for the expected intent or entities. Does the output contain the keys you need? Does the summary field contain more than just whitespace?
Layer 3: The LLM Inference Core (The Probabilistic Heart)
What it is: This is the call to the LLM itself- the source of all the non-determinism and the place where our old methods completely break down.
How to Test It: We must shift from testing to evaluation. Forget assert output == "...". Instead, we measure the quality of the output against a set of criteria.
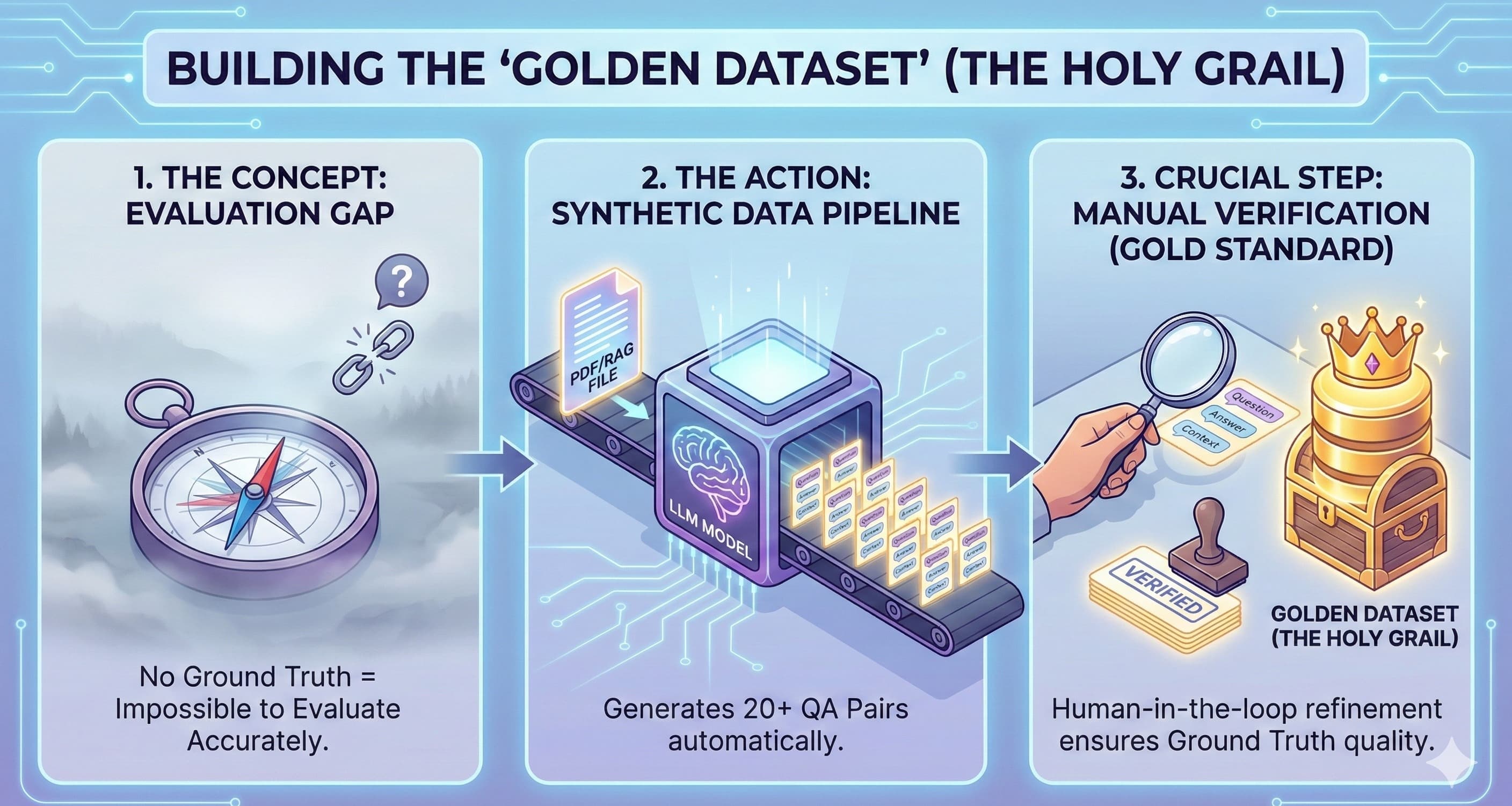
Golden Datasets: Curate a "golden set" of ideal prompt-and-response pairs that represent the desired behavior of your application. This becomes your ground truth for evaluation.
Semantic Similarity: Instead of an exact match, check if the LLM's output is semantically close to your golden answer. This is done by converting both strings into vector embeddings and measuring their distance. A common approach is to assert a high cosine similarity score: assert cosine_similarity(llm_output_embedding, golden_answer_embedding) > 0.9
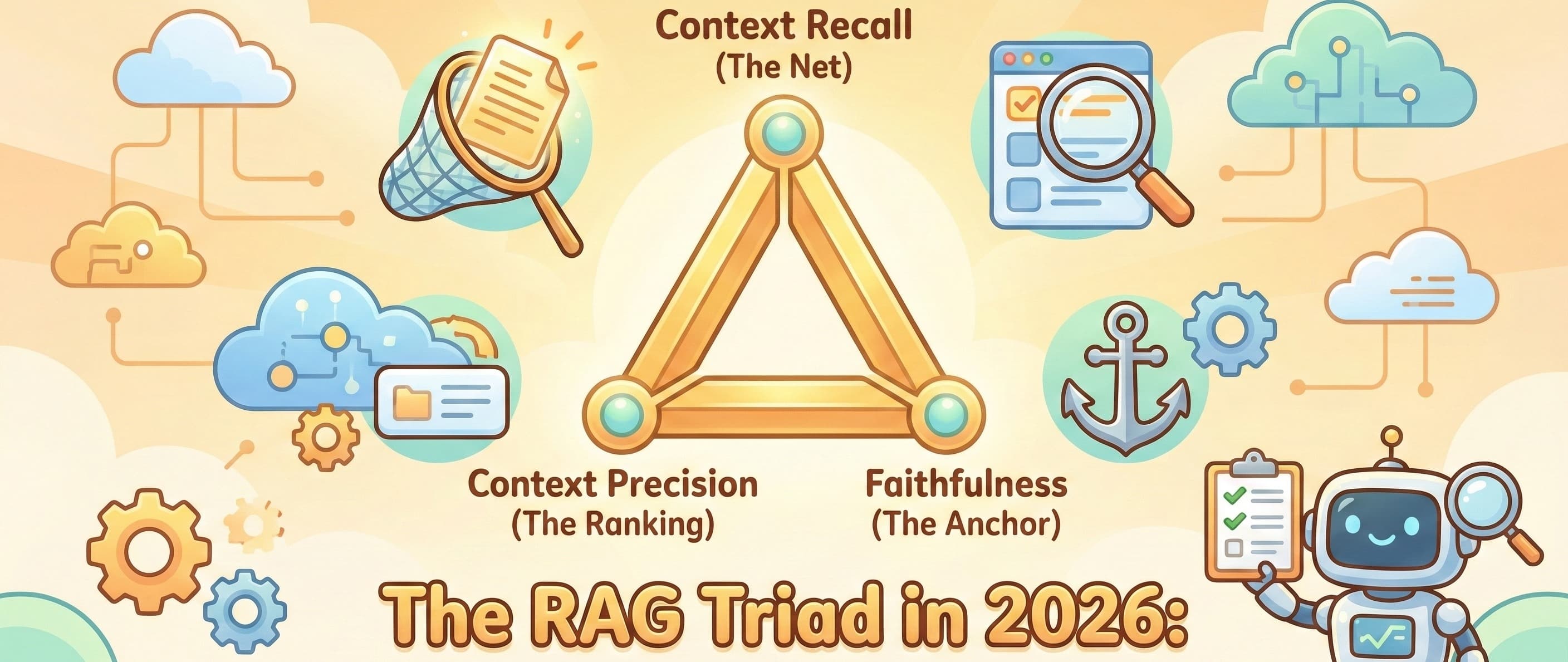
LLM-as-a-Judge: This is the state-of-the-art. Use a powerful model (like GPT-4) as an impartial judge to grade your application's LLM output. You feed the judge the original prompt, the generated answer, and a rubric (e.g., "On a scale of 1-5, was this answer helpful? Was it factually grounded in the provided context?"). This allows you to measure nuanced qualities like tone, creativity, and helpfulness at scale.
Behavioral & Capability Tests: Build specific test suites to evaluate core behaviors. Does the model refuse to answer harmful questions (Toxicity)? Does it correctly use a calculator tool when asked a math problem (Tool Use)? Does it avoid making up facts when using RAG (Hallucination)?
Putting It All Together: The Modern LLM QA Workflow
In practice, this new architecture changes your CI/CD pipeline. The "test" step is now an "evaluate" step.
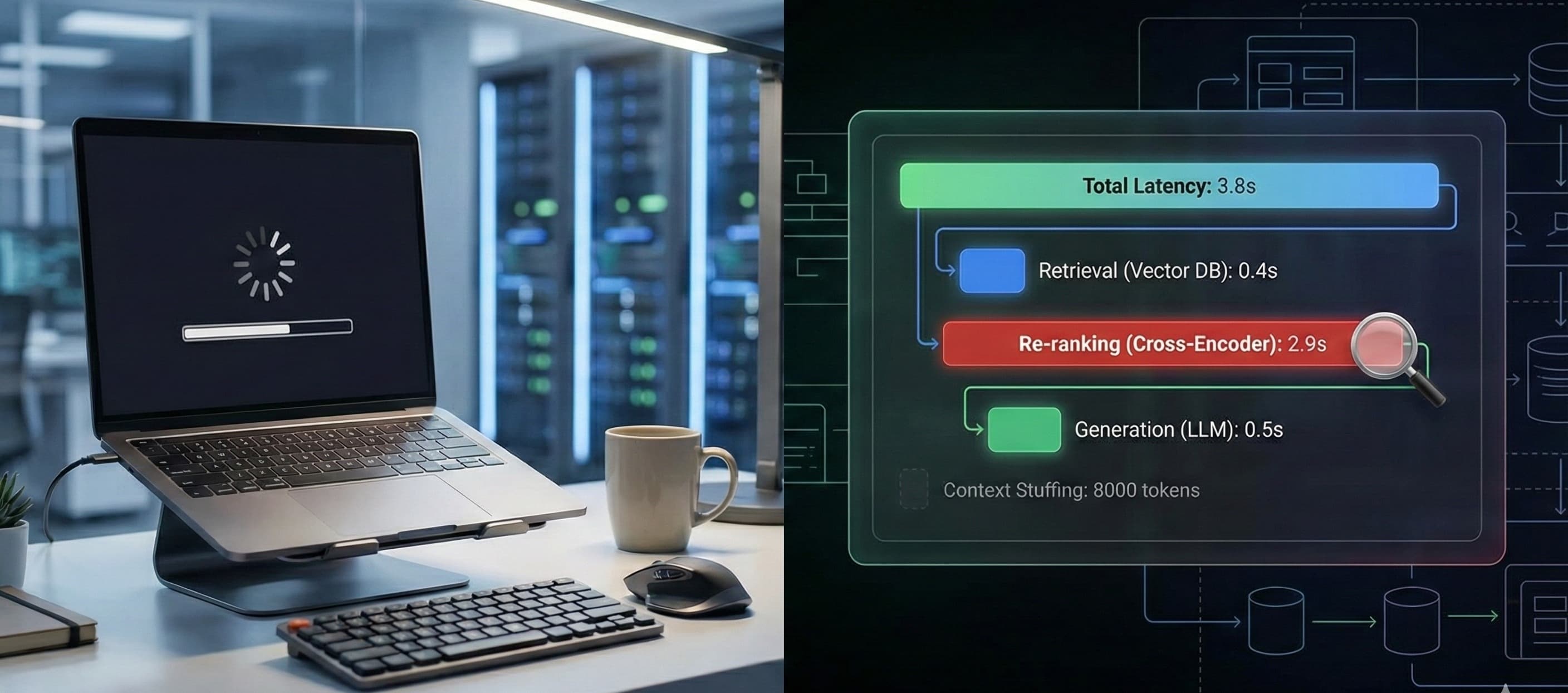
Offline Evaluation: Before merging to main, your pipeline runs the new code against your entire evaluation dataset. It doesn't produce a simple pass/fail. It produces a report: "Factual accuracy score is 92%, Tone adherence is 95%, Average response latency is 1.2s." You then gate your deployment on these scores meeting acceptable thresholds.
Online Monitoring: You aggressively log production interactions (with user consent) and feedback. This real-world data is the best source for identifying new edge cases and is used to continuously grow and refine your golden datasets.
Conclusion: From Test Engineer to Evaluation Scientist
The ground has shifted beneath our feet. Building reliable LLM applications requires us to evolve our roles. We are no longer just test engineers writing deterministic assertions; we are becoming evaluation scientists designing robust systems to measure model quality.
The central question is no longer, "Is the output exactly this?"
It is now, "Is the output semantically correct and behaviorally acceptable?"
This might seem daunting, but you can start small. Build your first golden dataset with just 10-20 ideal examples. Write your first semantic similarity test. That is your first, crucial step into this new paradigm. Welcome to the future of quality assurance.